「论文阅读」-Into the Unknown Unknowns: Engaged Human Learning Through Participation in Language Model Agent Conversations
Abstract
No Single, gold query, but queries evolve dynamically towards a goal.
目录
0x00 亮点
提出协作式STORM(Co-STORM)
不像QA系统要求用户询问所有问题。Co-STORM让用户观察,允许用户偶尔介入多个LM agents间的对话。
agents从用户视角问问题,使用户有可能偶然发现“自己不知道自己不知道”但有价值的观点或事物。
allow user to discover the unknown unknowns serendipitously.为了提高用户交互的便利性,Co-STORM可以通过将已发现的信息组织成动态思维导图,协助用户回顾谈话的过程,最终会生成一个综合性的报告。
在自动化质量评估方面,构建了WildSeek数据集。作者手机了与用户目标相关的真实信息搜集记录
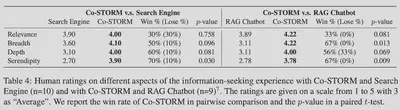
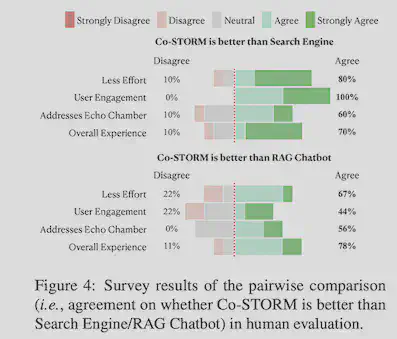
作者团队通过实验表明,70%使用者认为Co-STORM比搜索引擎好,78%使用者认为其比RAG机器人好。
0x01 引言
现有复杂信息获取系统的能力
传统搜索引擎和信息检索模型可以高效处理known unknowns,也就是说,当用户清楚地知道他们需要的信息时,这些系统可以通过生成直接的响应满足用户需求。
然而,当面临复杂信息获取场景时,如学术研究、市场分析、决策制定等,系统应该让用户可以发现unknown unknowns以促进知识发现。
什么是unknown unknowns
最早源自于军事上的概念,指代意料之外的风险(比如从未设想过的被打击方式)。在信息收集的上下文里,意为侥幸得到的发现(surendipitous discovery)。
Kirzner做过一个概念对比:
Surendipitous discovery
意识到忽略了在事实上可轻易得到的现成的某种东西.
“the realization that one had overlooked something in fact readily avilable.”
Successful search
一个人明确知道缺失的信息的(蓄意)产出
“the deliberate production of information which one know one had lacked”
STORM的能力和局限性
亮点:将语言模型和搜索引擎结合,对任意主题自动生成高质量的维基百科风格文章。
然而,STORM不支持用户交互,只能产出静态的报告作为最终结果。这在复杂信息收集场景下不够用,因为不存在单一的完美的查询词,查询通常会围绕着目标动态地变化。
……
Co-STORM的特点
不同于一问一答的交互,用户可以通过观察和偶尔参与对话进行学习,仿效了一种常见的教育场景。
为了促进启发式(thought-provoking)的对话和意外之喜,Co-STORM模拟了两种agent类型:
专家agent:从不同的角度提问或回答。
主持人agent:知道如何提出好问题和指引对话。
用户可以随时插话,引导对话或抛出问题或观点。
维护一个动态的、层次化的思维导图,确保用户容易理解和参与。
学习和信息获取的范例对比
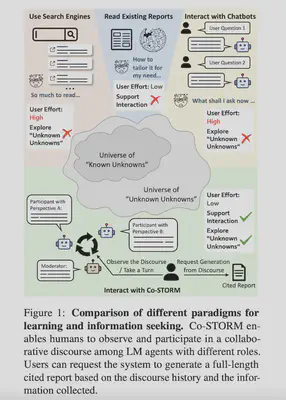
使用搜索引擎
痛点:需要阅读的东西太多,无法获得意外之喜(Unknown Unknowns)
阅读现有报告
痛点:需要费较大功夫裁剪内容以满足特定需要。不支持交互。
与聊天机器人交互
痛点:用户可能不知道该问什么。
与Co-STORM交互
0x02 复杂信息搜寻
问题形式化
复杂信息搜寻被Pirolli定义为拓宽认知过程的一部分,包括如下流程:
collecting infomation from large collections
收集信息
sifting
筛选信息
understanding
理解信息
organizing information
组织信息
这种工作方法流行于:
新闻调研
科学研究
市场分析
这类任务的属性:
要求从多个数据源中搜寻信息,以构建一个主题下的立体化描述。(不是为了检索出与某个查询词最匹配的一篇文档)
如研究主题“聚类”,可以从无监督学习、应用场景、聚类公理化探索等方面进行调研和组织内容。
涉及用户交互、而不是简单处理一个单一的查询。
产出一个报告形式的结果,而非一个简短的答案。
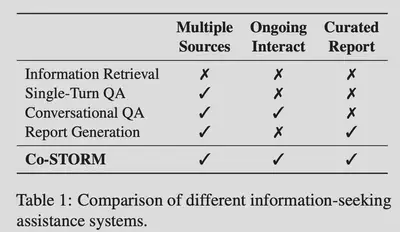
问题形式化:
给定初始兴趣主题$t$、初始目标$g$和信息库$R$,任务是与用户交互并写出一篇符合用户兴趣的长篇报告$S=s_1s_2…s_n$,每一个句子都引用信息集合$R$中的一个子集$I$
0x03 方法
本杰明·富兰克林:告诉我的事我会忘记,教我的事情我会记住,亲身参与的事情我会从中学习。
Tell me and I forget. Teach me and I remember. Involve me and I learn.
协作式讨论协议(Collaborative Discourse Protocol)
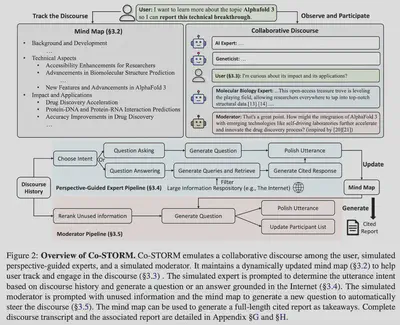
协作式讨论可表示为$D={u_1,u_2,…,u_n}$。
其中$u_i$是由用户、专家和主持人三类角色其中之一发表的(回合制)文本言论
讨论由N个专家发起,每个专家(附带独特视角)对主题t发表一轮见解,为接下来的讨论作热身。
言论意图(Utterance Intent)
ORIGINAL QUESTION:提出一个新问题
INFORMATION REQUEST:为先前的言论中寻找补充信息
POTENTIAL ANSWER:为之前抛出的问题提供一个可能的答案
FURTHER DETAILS:对先前的答案提供补充信息
将ORIGINAL QUESTION和INFORMATION REQUEST统一认定为question-asking,另外两类意图统一认为是question-answering。
主动权管理(Initiative Management)
Co-STORM采用混合主动权方法,当用户积极参与,系统会基于用户的问题或论点继续讨论,产出更精准的讨论。否则系统会自动进行下一轮次。
回合管理(Turn Management)
如果用户在时刻t没有主导谈话,Co-STORM需要决定哪个LM agent应该发表下一个言论:让不同的专家$p_1,…,p_N$按顺序发表言论,为了避免所有专家仅仅围绕一个论点讨论,在观测到L个连续的POTENTIAL ANSWER或FURTHER DETAILS意图的回答后,系统会让主持人介入对话。
基于思维导图跟踪讨论过程(Tracking the Discourse with a Mind Map)
对于协作而言,有一个共享知识库或共享概念空间十分重要。
用户参与(User Participation)
当用户发表言论$u$,Co-STORM基于$u$检索相关信息用于提示LM“邀请”一个专家团队$P^{’}$.随着专家团队更新, 系统转回自动引导模式,专家或主持人根据回合制管理协议轮流发表观点。
一旦用户对讨论满意,Co-STORM会生成最终的报告$S$。报告的生成会使用思维导图M作为提纲,还会根据每个概念$c$及检索到的相关信息$I^{c}$逐章节生成报告。
模拟圆桌会议参与者
- 如果没有用户或主持人的打断,专家会如何进行发表言论?
模拟主持人
- 如果没有主持人参与,所有参与讨论者都是专家,会如何?
0x04 Co-STORM的实现
Zero-Shot提示
使用DSPy框架
0x05 自动评估
Baselines:
RAG Chatbot
STORM+QA
自动化评估指标
报告质量
四个指标:
Relevance,相关性
Broad Coverage,广度
Depth,深度
Novelty,新颖度
基于7B的LM验证器,根据5-point rubric对报告进行打分。对信息多样性(Information Diversity)进行量化:信息的平均成对差异性。
$1-\frac{\sum_{i,j\in I,i\neq j cos(i,j)}}{|I|(|I|-1)}$
讨论质量(Discourse Quality)
在每个回合,对讨论内容进行评价。
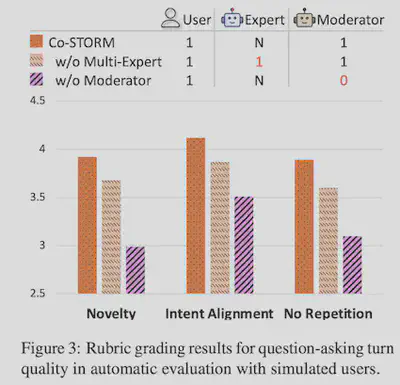
对于问题询问的言论,评估:
Novelty,新颖性
Intent Alignment,目的对齐
No repetition,无重复性
对于问题回答的言论,评估:
Consistency
Engagement
自动化评估结果
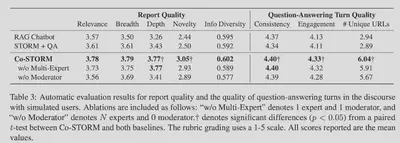
消融实验
0x06 人类评估
人类评估结果
0x07 相关工作
Information-Seeking Support in NLP
Multi-Agent System
Collaborative Discourse for Human Learning
0x08 总结
文章提出了Co-STORM系统,模拟用户和多个LM Agents间的合作讨论场景
实验结果及调研结果表明,Co-STORM在探索“Unknown Unknowns”方面比传统搜索引擎和RAG聊天机器人方面表现更为出色,并且用户在交互方面简单省力。
0x09 不足之处
系统可以考虑迎合用户层次,对于对讨论主题有丰富经验、知识的用户,可以跳过基本的事实和循序渐进的概念介绍。但对于新手则需要循序渐进从基础知识开始引导。
用户无法对讨论进行更精细的控制,比如管理专家的视角和自定义言论长度。
多语言支持。需要集成可以访问多种语言信息源的搜索引擎或检索模型。
不同语言的内容管理。需要鲁棒的内容审核并且识别存在矛盾的信息。
相比于RAG聊天机器人,Co-STORM有更高的延时,因为需要判别言论意图和更新思维导图,对于实时交互而言,需要考虑进一步优化效率。
关键问题
- 如何构建高质量数据集?主题和意图目标对
- 动态思维导图构建效率
- 如何评价报告质量?如何评价讨论的质量?
- ……..
Prompt设计要点
任务背景、工具提供、任务要求、输出要求。
动态更新思维导图
Agent被要求基于当前思维导图和用户输入,决定如何更新思维导图:为当前节点插入信息,或是构建新节点或处理其他节点。
操作集合:
insert
step: [child node name]
create: [new child node name]
输入:
用户意图:用户的问题或查询词
当前思维导图
模拟专家
- 根据用户问题设计查询词(Question2Query)
根据讨论的主题和用户问题设计查询词
- 问题回答(AnswerQuestion)
给定主题、问题和可参考信息,指定响应风格,给出回答。
模拟主持人
知识总结
生成下一个重要问题
选择专家
系统体验
主题:2024 年度最佳游戏
介入对话:
How do you think of Black Myth Wukong. Does it deserve the Game of The Year award?