「论文阅读」A Website Content Extraction Method Based on Text and Symbol Density
Abstract
大多数网站的网页除了主要的内容,还包含导航栏,广告,版权等无关信息。这些额外内容被称为噪声,通常与主题无关。本文提出基于网页文本密度和符号密度对网页进行正文内容提取,这是一种快速,准确通用的网页提取算法。
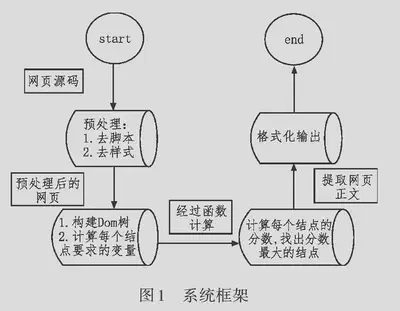
大多数网站的网页除了主要的内容,还包含导航栏,广告,版权等无关信息。这些额外内容被称为噪声,通常与主题无关。本文提出基于网页文本密度和符号密度对网页进行正文内容提取,这是一种快速,准确通用的网页提取算法。