让DeepResearch用户轻松评估文章质量的工具——Research Evaluator Agent
在学术研究和技术创新快速迭代的今天,分析师往往需要对大量文章、报告进行评估:从“覆盖面”(Breadth)到“深度”(Depth),再到“相关性”(Relevance)、“新颖度”(Novelty)乃至“准确性”(Factuality),每一个维度都至关重要。但传统的人工评审周期长、易受主观因素影响——如果有一套高效、可扩展、可定制的自动化评估方案,该多好?
Research Evaluator Agent 提供了一种黑盒评价方法。它将 AI 模型的理解和打分能力封装成一套可配置、可扩展的自动化评估流水线,帮你在几秒钟内获得多维度的文章评分和简要点评,再也不必在海量文档中手动“比对打分”。
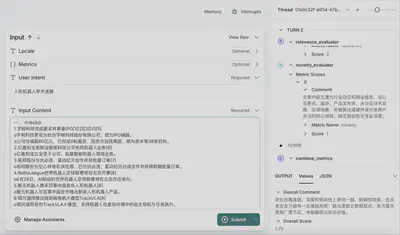
核心原理:多 Agent + 有向图工作流
项目将评估流程拆分为一张「有向图」(Directed Acyclic Graph):
Intent Interpreter(意图解析节点)
- 接收用户对“评价期待”的描述(如侧重哪些维度、希望输出格式等),通过预定义的 Prompt 模板,调用 LLM 输出一个结构化的上下文(
SharedContext)。 - 这样,无论评审者偏好中文/英文、表格式/要点式,都能在最前端统一规范。
- 接收用户对“评价期待”的描述(如侧重哪些维度、希望输出格式等),通过预定义的 Prompt 模板,调用 LLM 输出一个结构化的上下文(
Metric Evaluator(指标评估节点)
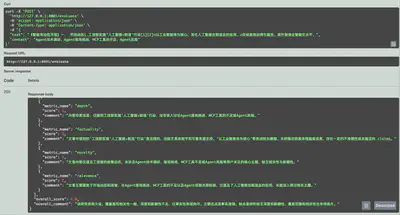
- 针对每个指标(breadth、depth、relevance、novelty、factuality),独立生成 Prompt,并行调用 LLM 得到打分和简要评语(
MetricScoreResult)。 - 并行化执行不仅速度极快,还能保证各个维度的评估逻辑完全隔离、互不干扰,易于新增自定义指标。
- 针对每个指标(breadth、depth、relevance、novelty、factuality),独立生成 Prompt,并行调用 LLM 得到打分和简要评语(
Combine Metrics(结果汇总节点)
- 按照配置文件中定义的权重(可灵活调整)计算最终综合得分;
- 再次调用 LLM,可选地生成一段面向用户的“整体点评”。
整个图由 langgraph 库驱动:开发者只需在配置文件(conf.yaml)写明需要哪些指标,框架就能动态构建节点、自动连接前后关系,并一键运行。
评分原则解读
下面以表格形式,逐项列出每个指标在 1~5 分的含义解读,方便直观对比和理解:
广度(Breadth)
| 分数 | 含义解读 |
|---|---|
| 1 | 非常狭窄,只覆盖单一小方面,遗漏大部分相关子主题 |
| 2 | 有限覆盖,仅涉及少数方面,但仍错过许多关键角度 |
| 3 | 中等覆盖,触及若干重要方面,但仍存在明显空白 |
| 4 | 良好覆盖,涵盖大部分主要方面,仅有少量次要遗漏 |
| 5 | 极佳覆盖,既包含所有主要方面,也兼顾次要细节,全面细致 |
深度(Depth)
| 分数 | 含义解读 |
|---|---|
| 1 | 表面化,仅给出高层次陈述,无实质性解释或论证 |
| 2 | 略有深度,包含少量细节或示例,但推理较浅 |
| 3 | 中等深度,提供了一些解释和案例,但缺乏充分展开 |
| 4 | 良好深度,分析详实、举例充分,推理较为严谨 |
| 5 | 卓越深度,论证全面、示例丰富,推理严谨且富有洞见 |
相关性(Relevance)
| 分数 | 含义解读 |
|---|---|
| 1 | 大部分内容离题,与用户意图关联性极差 |
| 2 | 相关性有限,偶有触及意图,但大部分内容偏离主题 |
| 3 | 中等相关,大约一半内容与意图匹配 |
| 4 | 高度相关,大部分内容紧扣意图,仅有少量偏离 |
| 5 | 完全相关,全文持续聚焦用户意图,内容精准支持 |
新颖度(Novelty)
| 分数 | 含义解读 |
|---|---|
| 1 | 缺乏新意,仅复述常见或众所周知的事实 |
| 2 | 新意微弱,引入少量平凡或与主题关联度不高的新观点 |
| 3 | 中度新颖,包含若干相关新想法,但未深入挖掘 |
| 4 | 良好新颖,提供了多条富有洞见且相关的新视角 |
| 5 | 极具新颖,大量独到且高度相关的洞见,超出常见认知 |
准确性(Factuality)
| 分数 | 含义解读 |
|---|---|
| 1 | 存在多处重大错误或无法验证的断言 |
| 2 | 有若干较严重的不准确之处或未经证实的说法 |
| 3 | 整体准确,仅有少量小错误或未验证的条目 |
| 4 | 准确度高,仅有极少或边缘性不确定信息 |
| 5 | 完全准确,所有声明皆可通过可靠来源逐条验证 |
工作流程简述
Research Evaluator Agent 用「多 Agent + 有向图」的方式,把整体流程拆分成三个阶段,每个阶段由不同的“节点”(Agent)负责:
- 需求解析(Intent Interpreter)
首先,它会读取你对评估的“期望”:比如侧重哪些维度、希望输出要点式还是表格化等,然后调用 AI 模型,生成一个结构化的上下文(SharedContext),保证后续所有节点都遵循相同的标准。
- 多维度打分(Metric Evaluator)
针对每个指标(广度、深度、相关性、新颖度、准确性),独立生成 Prompt 并行调用 AI 模型,为文档打分并给出简要说明(MetricScoreResult)。
并行化执行不仅速度快,还能轻松新增自定义指标:只需在配置文件里写一个新模板,无需改动核心代码。
- 结果汇总(Combine Metrics)
最后,根据配置好的权重计算综合分,并可再次调用模型生成整体点评。内置的 JSON 修复工具会自动校正模型输出,确保数据解析万无一失。
现有局限
- 模型依赖与成本
并行调用大型 AI 模型会产生不菲的费用,也受网络和服务波动影响,需要结合具体使用量做流量控制或考虑本地化模型部署。
- 领域专业化适应
默认模板偏通用内容,若需评估深度学习、生命科学或工程报告等领域文档,需要自行编写更专业的 Prompt。
- 可解释性有待提升
虽能给出简要评语,但 AI 的打分流程仍难以完全透明,无法替代专家深入点评。
- 隐私与安全
将文档发送到云端模型可能涉及数据保密问题,高度敏感文档需评估合规风险。
结语
如果你在论文点评、内容审核或教育测评等方面有痛点,不妨在项目中探索更多可能,贡献你的「定制指标」或「优化流程」。让 AI 赋能,从动机到落地。