资讯数据采集框架 && 新闻简报Agent Workflow
动机
- 市场各家AI搜索引擎后台策略及数据源质量不透明,不确保数据源高质量。
- 构建Agent时使用外部搜索引擎工具偶尔出现一些超长乱码返回,导致污染工作流整个上下文,示例情况如下:
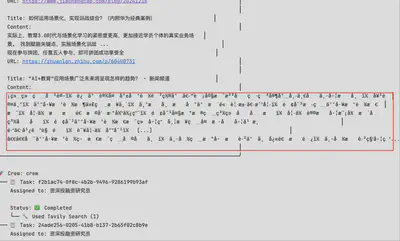
因此考虑自构建资讯类爬虫和内容结构化提取方法,通过自行筛选(可能也存在个人偏见)高质量数据源,利用AI进行资讯简报总结,高效了解市场信息。
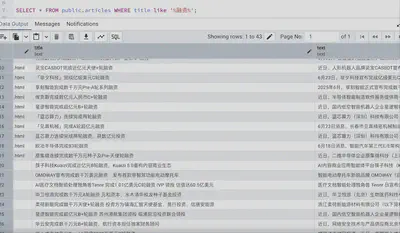
资讯类网站爬虫
特性
- 实现资讯类网站统一内容结构化爬取框架,通过简单配置实现大多数资讯类网站内容爬取
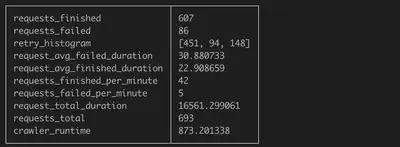
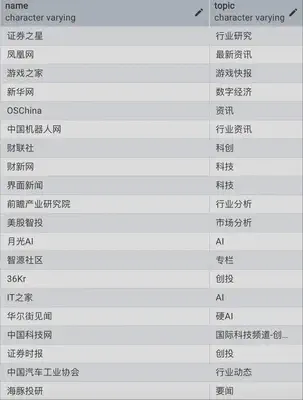
科技行业等数十个资讯网站采集爬虫积累,涵盖源包括(不断增长ing):
资讯简报
分析框架
结果示例
提示词片段
挑战
资讯类站点关键属性统一结构化方法
栏目
翻页
资讯基本要素:title、author、content、publish_time、source等
反爬
css in js:动态生成css
多数海外网站使用该类型框架编写前端。采集系统目前难以实施统一的资讯属性结构化。
登录验证:微信扫码、手机验证等
参考项目
GeneralNewsExtract
Newspaper3k