行业知识图谱构建及探索性分析项目(第一篇)
0x00 项目介绍
内容
解析国标行业分类2017数据,构建行业图谱
国标行业关系信息存储PostgreSQL
基于Neo4J存储国标行业图谱
基于图数据挖掘技术对行业图谱进行探索
社区结构探索
中心性探索
节点嵌入向量空间可视分析
……
技术栈
数据分析
- pandas(数据分析)
数据库操作
sqlalchemy(ORM操作postgres)
py2neo(操作neo4j)
数据存储
Redis(运行时缓存)
PostgreSQL(存储关系型数据)
Neo4J(存储图数据)
可视化
Neo4J Browser
Neo4J Bloom
Python Plotly
图数据挖掘
Neo4J Graph Science
Python
原理总结
图数据挖掘
节点嵌入
节点中心性
网络社区结构
节点邻域分析
0x01 数据演示-行业图谱
关系数据展示
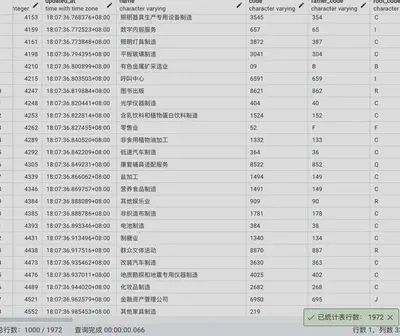
统计各行业门类所包含的子行业数量
select g1.root_code, g2.name, count(*) FROM public.gb_industry g1 JOIN public.gb_industry g2 ON g1.root_code=g2.code group by g1.root_code, g2.name order by g1.root_code;

由数据可见制造业体系之庞大。
图数据展示
查询地理相关行业图谱:
MATCH (n:IndustryGB)
WHERE n.name contains '地理'
RETURN n

行业图谱整体结构:
查询制造业相关行业图谱:
MATCH (n {name:'制造业'}) RETURN n

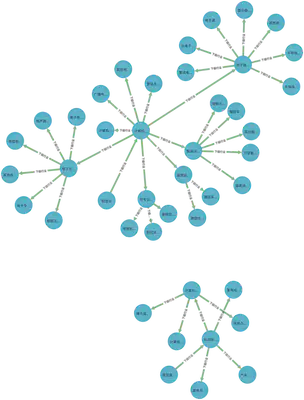
计算机相关行业
MATCH (n)-[]->() WHERE n.name contains '计算机' RETURN n
0x02 图挖掘示例
节点嵌入
基于Neo4J GDS的Node2Vec计算
Node2Vec - Neo4j Graph Data Science
通过cypher对图谱中的节点进行node2vec嵌入学习,输出2维、3维嵌入表示便于可视化。
创建和删除图:
CALL gds.graph.project('IndustryGraph', ['IndustryGB', 'IndustryGB'], 'DOWNLEVEL_INDUSTRY');
// 如果需要重新构造图,可以先删除,再重构
CALL gds.graph.drop('IndustryGraph')
参数配置1: 迭代1w次,随机游走步长10,输出2维嵌入表示
CALL gds.node2vec.stream('IndustryGraph',
{embeddingDimension: 2,iterations: 10000, walkLength:10})
YIELD nodeId, embedding
RETURN nodeId, embedding
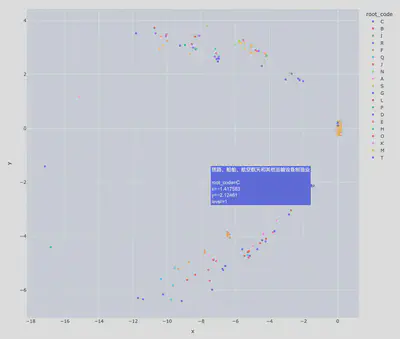
参数配置2:迭代1000次,随机游走步长3,输出2维嵌入表示
CALL gds.node2vec.stream('IndustryGraph',
{embeddingDimension: 2,iterations: 1000, walkLength:3, windowSize:5})
YIELD nodeId, embedding
RETURN nodeId, embedding
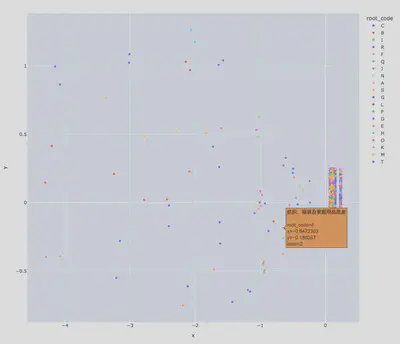
参数配置3: 迭代100次,随机游走步长3,输出2维嵌入表示
CALL gds.node2vec.stream('IndustryGraph', {embeddingDimension: 2,iterations: 100, walkLength:3, windowSize:5})
YIELD nodeId, embedding
RETURN nodeId, embedding
可视化
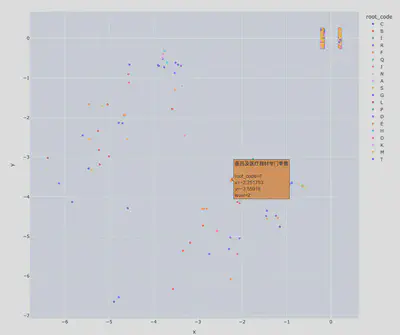
问题
不确定是否是参数未调好还是2维嵌入表达能力不足的问题,个人觉得node2vec输出的节点嵌入向量对原本图结构信息的编码能力不足:少部分节点表现出聚类趋势,基本正确,但大多数节点聚集在一起,表现出不可分的趋势。

基于Neo4J GDS的HashGNN计算
HashGNN - Neo4j Graph Data Science
CALL gds.hashgnn.stream('IndustryGraph', { nodeLabels:['IndustryGB'],binarizeFeatures: {dimension: 2, threshold: 32},iterations:1000, featureProperties:['root_code'], embeddingDensity: 2})
YIELD nodeId, embedding
RETURN nodeId, embedding

参考官方文档执行命令未成功,提示指定属性并非所有节点都有,但实际上所有节点都有该属性且不为空。
FastRP
CALL gds.fastRP.stream('IndustryGraph',
{
embeddingDimension: 2,
randomSeed: 42
}
)
YIELD nodeId, embedding

突然想到一个问题:基于行业节点名的词嵌入经过聚类能在多大程度上还原行业分类情况?行业的分类应该基于哪些根本特征进行划分?
节点中心性探索
PageRank
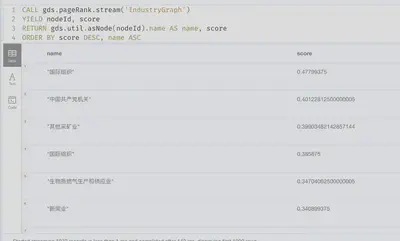
CALL gds.pageRank.stream('IndustryGraph')
YIELD nodeId, score
RETURN gds.util.asNode(nodeId).name AS name, score
ORDER BY score DESC, name ASC
CALL gds.pageRank.stream('IndustryGraph')
YIELD nodeId, score
RETURN gds.util.asNode(nodeId).name AS name, gds.util.asNode(nodeId).level AS level, score
ORDER BY score ASC

Betweeness Centrality
CALL gds.betweenness.stream('IndustryGraph')
YIELD nodeId, score
RETURN gds.util.asNode(nodeId).name AS name, gds.util.asNode(nodeId).level AS level, score,gds.util.asNode(nodeId).code AS code
ORDER BY score DESC

Closeness Centrality
Closeness Centrality - Neo4j Graph Data Science
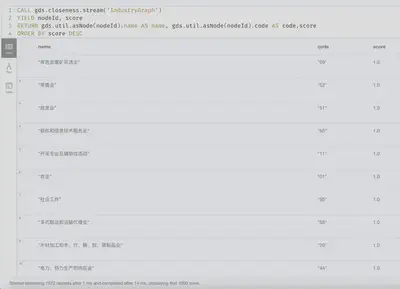
CALL gds.closeness.stream('IndustryGraph')
YIELD nodeId, score
RETURN gds.util.asNode(nodeId).name AS name, gds.util.asNode(nodeId).code AS code,score
ORDER BY score DESC
HITS
https://neo4j.com/docs/graph-data-science/current/algorithms/hits/
CALL gds.hits.stream('IndustryGraph', {hitsIterations: 20})
YIELD nodeId, values
RETURN gds.util.asNode(nodeId).name AS Name, values.auth AS auth, values.hub as hub
ORDER BY hub desc

社区结构探索
基于GDS的社区结构分析
Community detection - Neo4j Graph Data Science
LabelPropagation
CALL gds.labelPropagation.stream('IndustryGraph')
YIELD nodeId, communityId AS Community
RETURN gds.util.asNode(nodeId).name AS Name, gds.util.asNode(nodeId).root_code AS Class,Community
ORDER BY Community, Name
Strong Connected Components
强连通分支
CALL gds.scc.stream('IndustryGraph', {})
YIELD nodeId, componentId
RETURN gds.util.asNode(nodeId).name AS Name, componentId AS Component
ORDER BY Component DESC
Week Connected Components
弱连通分支
CALL gds.wcc.stream('IndustryGraph')
YIELD nodeId, componentId
RETURN gds.util.asNode(nodeId).name AS name, componentId
ORDER BY componentId, name
节点邻域分析
Ricci Flow