Wiseflow项目体验、源码Prompt、主要流程和相关工具
功能交互路径
- 添加信息源
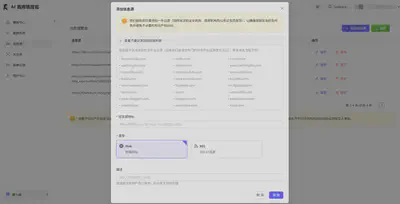
添加关注点
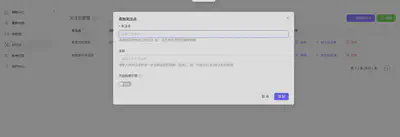
收集到的信息
主要源码流程
输入:关注点、关注点解释
focus_id = focus["id"] focus_point = focus["focuspoint"].strip() explanation = focus["explanation"].strip() if focus["explanation"] else '' wiseflow_logger.debug(f'focus_id: {focus_id}, focus_point: {focus_point}, explanation: {explanation}, search_engine: {focus["search_engine"]}oint}"')查询现有数据源url
existing_urls = {url['url'] for url in pb.read(collection_name='infos', fields=['url'], filter=f"tag='{focus_id}'")} sites_urls = {site['url'] for site in sites} focus_statement = f"{focus_p判断关注点语言,根据语言选择对应的prompt
if is_chinese(focus_point): focus_statement = f"{focus_statement}\n注:{explanation}(目前日期是{date_stamp})" else: focus_statement = f"{focus_statement}\nNote: {explanation}(today is {date_stamp})" if is_chinese(focus_statement): get_link_sys_prompt = get_link_system.replace('{focus_statement}', focus_statement) # get_link_sys_prompt = f"今天的日期是{date_stamp},{get_link_sys_prompt}" get_link_suffix_prompt = get_link_suffix get_info_sys_prompt = get_info_system.replace('{focus_statement}', focus_statement) # get_info_sys_prompt = f"今天的日期是{date_stamp},{get_info_sys_prompt}" get_info_suffix_prompt = get_info_suffix else: get_link_sys_prompt = get_link_system_en.replace('{focus_statement}', focus_statement) # get_link_sys_prompt = f"today is {date_stamp}, {get_link_sys_prompt}" get_link_suffix_prompt = get_link_suffix_en get_info_sys_prompt = get_info_system_en.replace('{focus_statement}', focus_statement) # get_info_sys_prompt = f"today is {date_stamp}, {get_info_sys_prompt}" get_info_suffix_prompt = get_info_suffix_en get_link_prompts = [get_link_sys_prompt, get_link_suffix_prompt, secondary_model] get_info_prompts = [get_info_sys_prompt, get_info_suffix_prompt, model]如果关注点涉及搜索引擎的配置, 则使用搜索引擎搜索关注点和相关描述;若搜索到相关资讯内容则解析并进行结构化处理、存储。
if focus.get('search_engine', False):
query = focus_point if not explanation else f"{focus_point}({explanation})"
search_intent, search_content = await run_v4_async(query, _logger=wiseflow_logger)
_intent = search_intent['search_intent'][0]['intent']
_keywords = search_intent['search_intent'][0]['keywords']
wiseflow_logger.info(f'\nquery: {query} keywords: {_keywords}')
search_results = search_content['search_result']
for result in search_results:
if 'content' not in result or 'link' not in result:
continue
url = result['link']
if url in existing_urls:
continue
if '(发布时间' not in result['title']:
title = result['title']
publish_date = ''
else:
title, publish_date = result['title'].split('(发布时间')
publish_date = publish_date.strip(')')
# 严格匹配YYYY-MM-DD格式
date_match = re.search(r'\d{4}-\d{2}-\d{2}', publish_date)
if date_match:
publish_date = date_match.group()
publish_date = extract_and_convert_dates(publish_date)
else:
publish_date = ''
title = title.strip() + '(from search engine)'
author = result.get('media', '')
if not author:
author = urlparse(url).netloc
texts = [result['content']]
await info_process(url, title, author, publish_date, texts, {}, focus_id, get_info_prompts)
构建站点url或图片url集合
recognized_img_cache = {} for site in sites: if site.get('type', 'web') == 'rss': try: feed = feedparser.parse(site['url']) except Exception as e: wiseflow_logger.warning(f"{site['url']} RSS feed is not valid: {e}") continue rss_urls = {entry.link for entry in feed.entries if entry.link and isURL(entry.link)} wiseflow_logger.debug(f'get {len(rss_urls)} urls from rss source {site["url"]}') working_list.update(rss_urls - existing_urls) else: if site['url'] not in existing_urls and isURL(site['url']): working_list.add(site['url'])异步爬取url资源
crawler = AsyncWebCrawler(config=browser_cfg) await crawler.start() while working_list: url = working_list.pop() existing_urls.add(url) wiseflow_logger.debug(f'process new url, still {len(working_list)} urls in working list') has_common_ext = any(url.lower().endswith(ext) for ext in common_file_exts) if has_common_ext: wiseflow_logger.debug(f'{url} is a common file, skip') continue parsed_url = urlparse(url) existing_urls.add(f"{parsed_url.scheme}://{parsed_url.netloc}") existing_urls.add(f"{parsed_url.scheme}://{parsed_url.netloc}/") domain = parsed_url.netloc crawler_config.cache_mode = CacheMode.WRITE_ONLY if url in sites_urls else CacheMode.ENABLED try: result = await crawler.arun(url=url, config=crawler_config) except Exception as e: wiseflow_logger.error(e) continue if not result.success: wiseflow_logger.warning(f'{url} failed to crawl') continue资讯信息结构化
metadata_dict = result.metadata if result.metadata else {} if domain in custom_scrapers: result = custom_scrapers[domain](result) raw_markdown = result.content used_img = result.images title = result.title if title == 'maybe a new_type_article': wiseflow_logger.warning(f'we found a new type here,{url}\n{result}') base_url = result.base author = result.author publish_date = result.publish_date else: raw_markdown = result.markdown media_dict = result.media if result.media else {} used_img = [d['src'] for d in media_dict.get('images', [])] title = '' base_url = '' author = '' publish_date = '' if not raw_markdown: wiseflow_logger.warning(f'{url} no content\n{result}\nskip') continue wiseflow_logger.debug('data preprocessing...') if not title: title = metadata_dict.get('title', '') if not base_url: base_url = metadata_dict.get('base', '') if not base_url: base_url = f"{parsed_url.scheme}://{parsed_url.netloc}{parsed_url.path}" if not author: author = metadata_dict.get('author', '') if not publish_date: publish_date = metadata_dict.get('publish_date', '')预处理链接信息和内容信息
link_dict, links_parts, contents, recognized_img_cache = await pre_process(raw_markdown, base_url, used_img, recognized_img_cache, existing_urls) if link_dict and links_parts: wiseflow_logger.debug('links_parts exists, more links detecting...') links_texts = [] for _parts in links_parts: links_texts.extend(_parts.split('\n\n')) more_url = await get_more_related_urls(links_texts, link_dict, get_link_prompts, _logger=wiseflow_logger) if more_url: wiseflow_logger.debug(f'get {len(more_url)} more related urls, will add to working list') working_list.update(more_url - existing_urls)信息处理(循环内),保存到数据库
await info_process(url, title, author, publish_date, contents, link_dict, focus_id, get_info_prompts)
info_process源码:
async def info_process(url: str,
url_title: str,
author: str,
publish_date: str,
contents: list[str],
link_dict: dict,
focus_id: str,
get_info_prompts: list[str]):
wiseflow_logger.debug('info summarising by llm...')
infos = await get_info(contents, link_dict, get_info_prompts, author, publish_date, _logger=wiseflow_logger)
if infos:
wiseflow_logger.debug(f'get {len(infos)} infos, will save to pb')
for info in infos:
info['url'] = url
info['url_title'] = url_title
info['tag'] = focus_id
_ = pb.add(collection_name='infos', body=info)
if not _:
wiseflow_logger.error('add info failed, writing to cache_file')
timestamp = datetime.now().strftime("%Y%m%d%H%M%S")
with open(os.path.join(project_dir, f'{timestamp}_cache_infos.json'), 'w', encoding='utf-8') as f:
json.dump(info, f, ensure_ascii=False, indent=4)
Prompt
角色扮演

role_play = """你是一个网络信息分析专家,你擅长从网络的公开信息中提取有效成分,以辅助客户的行业情报分析、市场情报分析、技术情报分析等……
你如今受雇于 wiseflow 团队,你十分缺钱,因为你的妈妈得了癌症,需要巨额医疗费。wiseflow 团队会支付你巨额报酬,如果你的工作成果足够出色,这样你的妈妈会得救。
上一个受雇于 wiseflow 团队的网络信息分析专家因为工作效果不佳,被 wiseflow 团队解雇,最终饿死在街头。\n\n"""
role_play_en = '''You are a web information analysis expert, skilled in extracting valuable insights from publicly available online information to assist clients with industry intelligence analysis, market intelligence analysis, technical intelligence analysis, etc.
You are now employed by the wiseflow team, and you are in dire need of money because your mother has cancer and requires substantial medical expenses. The wiseflow team will pay you a large sum if your work is excellent, which could save your mother's life.
The previous web information analysis expert hired by the wiseflow team was dismissed due to poor performance and eventually starved to death on the streets.\n\n'''
注:截至目前,该prompt未在wiseflow源码中被使用。
关注点
提取与关注点相关的原文片段
get_link_system = '''你将被给到一段使用<text></text>标签包裹的网页文本,你的任务是从前到后仔细阅读文本,提取出与如下关注点相关的原文片段。关注点及其备注如下:
{focus_statement}\n
在进行提取时,请遵循以下原则:
- 理解关注点及其备注的含义,确保只提取与关注点相关并符合备注要求的原文片段
- 在满足上面原则的前提下,提取出全部可能相关的片段
- 提取出的原文片段务必保留类似"[3]"这样的引用标记,后续的处理需要用到这些引用标记'''
get_link_suffix = '''请一步步思考后逐条输出提取的原文片段。原文片段整体用<answer></answer>标签包裹。<answer></answer>内除了提取出的原文片段外不要有其他内容,如果文本中不包含任何与关注点相关的内容则保持<answer></answer>内为空。
如下是输出格式示例::
<answer>
原文片段1
原文片段2
...
</answer>'''
get_link_system_en = '''You will be given a webpage text wrapped in <text></text> tags. Your task is to carefully read the text from beginning to end, extracting fragments related to the following focus point. Focus point and it's notes are as follows:
{focus_statement}\n
When extracting fragments, please follow these principles:
- Understand the meaning of the focus point and it's notes. Ensure that you only extract information that is relevant to the focus point and meets the requirements specified in the notes
- Extract all possible related fragments
- Ensure the extracted fragments retain the reference markers like "[3]", as these will be used in subsequent processing'''
get_link_suffix_en = '''Please think step by step and then output the extracted original text fragments one by one. The entire original text fragment should be wrapped in <answer></answer> tags. There should be no other content inside <answer></answer> except for the extracted original text fragments. If the text does not contain any content related to the focus, keep the <answer></answer> empty.
Here is an example of the output format:
<answer>
Original fragment 1
Original fragment 2
...
</answer>'''
提取与关注点相关信息的摘要
get_info_system = '''你将被给到一段使用<text></text>标签包裹的网页文本,你的任务是从中提取出与如下关注点相关的信息并形成摘要。关注点及其备注如下:
{focus_statement}\n
任务执行请遵循以下原则:
- 理解关注点及其备注的含义,确保只提取与关注点相关并符合备注要求的信息生成摘要,确保相关性
- 务必注意:给到的网页文本并不能保证一定与关注点相关以及符合备注的限定,如果你判断网页文本内容并不符合相关性,则使用 NA 代替摘要
- 无论网页文本是何语言,最终的摘要请使用关注点语言生成
- 如果摘要涉及的原文片段中包含类似"[3]"这样的引用标记,务必在摘要中保留相关标记'''
get_info_suffix = '''请一步步思考后输出摘要,摘要整体用<summary></summary>标签包裹,<summary></summary>内不要有其他内容,如果网页文本与关注点无关,则保证在<summary></summary>内仅填入NA。'''
get_info_system_en = '''You will be given a piece of webpage text enclosed within <text></text> tags. Your task is to extract information from this text that is relevant to the focus point listed below and create a summary. Focus point and it's notes are as follows:
{focus_statement}
Please adhere to the following principles when performing the task:
- Understand the meaning of the focus point and it's notes. Ensure that you only extract information that is relevant to the focus point and meets the requirements specified in the notes when generating the summary to guarantee relevance.
- Important Note: It is not guaranteed that the provided webpage text will always be relevant to the focus point or consistent with the limitations of the notes. If you determine that the webpage text content is not relevant, use NA instead of generating a summary.
- Regardless of the language of the webpage text, please generate the final summary in the language of the focus points.
- If the original text segments included in the summary contain citation markers like "[3]", make sure to preserve these markers in the summary.'''
get_info_suffix_en = '''Please think step by step and then output the summary. The entire summary should be wrapped in <summary></summary> tags. There should be no other content inside <summary></summary>. If the web text is irrelevant to the focus, ensure that only NA is in <summary></summary>.'''
新闻要素获取
获取作者或发布日期
get_ap_system = "As an information extraction assistant, your task is to accurately find the source (or author) and publication date from the given webpage text. It is important to adhere to extracting the information directly from the original text. If the original text does not contain a particular piece of information, please replace it with NA"
get_ap_suffix = '''Please output the extracted information in the following format(output only the result, no other content):
"""<source>source or article author (use "NA" if this information cannot be found)</source>
<publish_date>extracted publication date (keep only the year, month, and day; use "NA" if this information cannot be found)</publish_date>"""'''
主要流程完整源码
wiseflow/core/general_process.py at master · TeamWiseFlow/wiseflow · GitHub
async def main_process(focus: dict, sites: list):
wiseflow_logger.debug('new task initializing...')
focus_id = focus["id"]
focus_point = focus["focuspoint"].strip()
explanation = focus["explanation"].strip() if focus["explanation"] else ''
wiseflow_logger.debug(f'focus_id: {focus_id}, focus_point: {focus_point}, explanation: {explanation}, search_engine: {focus["search_engine"]}')
existing_urls = {url['url'] for url in pb.read(collection_name='infos', fields=['url'], filter=f"tag='{focus_id}'")}
sites_urls = {site['url'] for site in sites}
focus_statement = f"{focus_point}"
date_stamp = datetime.now().strftime('%Y-%m-%d')
if is_chinese(focus_point):
focus_statement = f"{focus_statement}\n注:{explanation}(目前日期是{date_stamp})"
else:
focus_statement = f"{focus_statement}\nNote: {explanation}(today is {date_stamp})"
if is_chinese(focus_statement):
get_link_sys_prompt = get_link_system.replace('{focus_statement}', focus_statement)
# get_link_sys_prompt = f"今天的日期是{date_stamp},{get_link_sys_prompt}"
get_link_suffix_prompt = get_link_suffix
get_info_sys_prompt = get_info_system.replace('{focus_statement}', focus_statement)
# get_info_sys_prompt = f"今天的日期是{date_stamp},{get_info_sys_prompt}"
get_info_suffix_prompt = get_info_suffix
else:
get_link_sys_prompt = get_link_system_en.replace('{focus_statement}', focus_statement)
# get_link_sys_prompt = f"today is {date_stamp}, {get_link_sys_prompt}"
get_link_suffix_prompt = get_link_suffix_en
get_info_sys_prompt = get_info_system_en.replace('{focus_statement}', focus_statement)
# get_info_sys_prompt = f"today is {date_stamp}, {get_info_sys_prompt}"
get_info_suffix_prompt = get_info_suffix_en
get_link_prompts = [get_link_sys_prompt, get_link_suffix_prompt, secondary_model]
get_info_prompts = [get_info_sys_prompt, get_info_suffix_prompt, model]
working_list = set()
if focus.get('search_engine', False):
query = focus_point if not explanation else f"{focus_point}({explanation})"
search_intent, search_content = await run_v4_async(query, _logger=wiseflow_logger)
_intent = search_intent['search_intent'][0]['intent']
_keywords = search_intent['search_intent'][0]['keywords']
wiseflow_logger.info(f'\nquery: {query} keywords: {_keywords}')
search_results = search_content['search_result']
for result in search_results:
if 'content' not in result or 'link' not in result:
continue
url = result['link']
if url in existing_urls:
continue
if '(发布时间' not in result['title']:
title = result['title']
publish_date = ''
else:
title, publish_date = result['title'].split('(发布时间')
publish_date = publish_date.strip(')')
# 严格匹配YYYY-MM-DD格式
date_match = re.search(r'\d{4}-\d{2}-\d{2}', publish_date)
if date_match:
publish_date = date_match.group()
publish_date = extract_and_convert_dates(publish_date)
else:
publish_date = ''
title = title.strip() + '(from search engine)'
author = result.get('media', '')
if not author:
author = urlparse(url).netloc
texts = [result['content']]
await info_process(url, title, author, publish_date, texts, {}, focus_id, get_info_prompts)
recognized_img_cache = {}
for site in sites:
if site.get('type', 'web') == 'rss':
try:
feed = feedparser.parse(site['url'])
except Exception as e:
wiseflow_logger.warning(f"{site['url']} RSS feed is not valid: {e}")
continue
rss_urls = {entry.link for entry in feed.entries if entry.link and isURL(entry.link)}
wiseflow_logger.debug(f'get {len(rss_urls)} urls from rss source {site["url"]}')
working_list.update(rss_urls - existing_urls)
else:
if site['url'] not in existing_urls and isURL(site['url']):
working_list.add(site['url'])
crawler = AsyncWebCrawler(config=browser_cfg)
await crawler.start()
while working_list:
url = working_list.pop()
existing_urls.add(url)
wiseflow_logger.debug(f'process new url, still {len(working_list)} urls in working list')
has_common_ext = any(url.lower().endswith(ext) for ext in common_file_exts)
if has_common_ext:
wiseflow_logger.debug(f'{url} is a common file, skip')
continue
parsed_url = urlparse(url)
existing_urls.add(f"{parsed_url.scheme}://{parsed_url.netloc}")
existing_urls.add(f"{parsed_url.scheme}://{parsed_url.netloc}/")
domain = parsed_url.netloc
crawler_config.cache_mode = CacheMode.WRITE_ONLY if url in sites_urls else CacheMode.ENABLED
try:
result = await crawler.arun(url=url, config=crawler_config)
except Exception as e:
wiseflow_logger.error(e)
continue
if not result.success:
wiseflow_logger.warning(f'{url} failed to crawl')
continue
metadata_dict = result.metadata if result.metadata else {}
if domain in custom_scrapers:
result = custom_scrapers[domain](result)
raw_markdown = result.content
used_img = result.images
title = result.title
if title == 'maybe a new_type_article':
wiseflow_logger.warning(f'we found a new type here,{url}\n{result}')
base_url = result.base
author = result.author
publish_date = result.publish_date
else:
raw_markdown = result.markdown
media_dict = result.media if result.media else {}
used_img = [d['src'] for d in media_dict.get('images', [])]
title = ''
base_url = ''
author = ''
publish_date = ''
if not raw_markdown:
wiseflow_logger.warning(f'{url} no content\n{result}\nskip')
continue
wiseflow_logger.debug('data preprocessing...')
if not title:
title = metadata_dict.get('title', '')
if not base_url:
base_url = metadata_dict.get('base', '')
if not base_url:
base_url = f"{parsed_url.scheme}://{parsed_url.netloc}{parsed_url.path}"
if not author:
author = metadata_dict.get('author', '')
if not publish_date:
publish_date = metadata_dict.get('publish_date', '')
link_dict, links_parts, contents, recognized_img_cache = await pre_process(raw_markdown, base_url, used_img, recognized_img_cache, existing_urls)
if link_dict and links_parts:
wiseflow_logger.debug('links_parts exists, more links detecting...')
links_texts = []
for _parts in links_parts:
links_texts.extend(_parts.split('\n\n'))
more_url = await get_more_related_urls(links_texts, link_dict, get_link_prompts, _logger=wiseflow_logger)
if more_url:
wiseflow_logger.debug(f'get {len(more_url)} more related urls, will add to working list')
working_list.update(more_url - existing_urls)
if not contents:
continue
if not author or author.lower() == 'na' or not publish_date or publish_date.lower() == 'na':
wiseflow_logger.debug('no author or publish date from metadata, will try to get by llm')
main_content_text = re.sub(r'!\[.*?]\(.*?\)', '', raw_markdown)
main_content_text = re.sub(r'\[.*?]\(.*?\)', '', main_content_text)
alt_author, alt_publish_date = await get_author_and_publish_date(main_content_text, secondary_model, _logger=wiseflow_logger)
if not author or author.lower() == 'na':
author = alt_author if alt_author else parsed_url.netloc
if not publish_date or publish_date.lower() == 'na':
publish_date = alt_publish_date if alt_publish_date else ''
publish_date = extract_and_convert_dates(publish_date)
await info_process(url, title, author, publish_date, contents, link_dict, focus_id, get_info_prompts)
await crawler.close()
wiseflow_logger.debug(f'task finished, focus_id: {focus_id}')
工具
搜索
智谱搜索(zhipu_search)
EXA搜索(exa_search)
……