基于TextRank的新闻文本摘要算法及结合落地场景的一些改进
算法原理概览
与PageRank类似,但任务从网页排序变为对文本中的句子进行排序。
整体算法流程:
文本预处理
定义句子相似性度量
构建句子相似图
迭代更新句子重要性分数
选择最重要的N个句子作为文本摘要
文本预处理
文本断句
过滤噪音句子
句子分词
句子相似度度量
最常用的度量方法:根据两个句子的共现词频衡量相似程度,共现词越多、频率越高句子越相似。

def _rate_sentences_edge(words1, words2):
rank = sum(words2.count(w) for w in words1)
if rank == 0:
return 0.0
assert len(words1) > 0 and len(words2) > 0
norm = math.log(len(words1)) + math.log(len(words2))
if numpy.isclose(norm, 0.):
# This should only happen when words1 and words2 only have a single word.
# Thus, rank can only be 0 or 1.
assert rank in (0, 1)
return float(rank)
else:
return rank / norm
也可以考虑使用句向量模型对句嵌入向量计算相似性
迭代更新句子重要性得分
使用经典的幂方法。
@staticmethod
def power_method(matrix, epsilon):
transposed_matrix = matrix.T
sentences_count = len(matrix)
p_vector = numpy.array([1.0 / sentences_count] * sentences_count)
lambda_val = 1.0
while lambda_val > epsilon:
next_p = numpy.dot(transposed_matrix, p_vector)
lambda_val = numpy.linalg.norm(numpy.subtract(next_p, p_vector))
p_vector = next_p
return p_vector
问题及解决办法
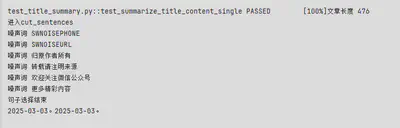
噪音
- 广告文本(可能含有电话、网址、关注公众号等)


- 版权声明

非文本样式影响断句
如原文本在换行或分句使用了html标记语言,如
。重复但明显无实际意义的句子
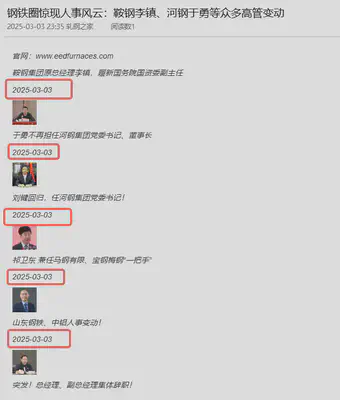
……
关键词过滤规则
比如通常的噪音句子中会包含下列关键词:
noise_token = ['欢迎关注微信公众号', '本文来源网络', '点击阅读原文', '点击蓝字关注', '点击蓝字','转载请注明来源', '归原作者所有','更多精彩内容']
可以在构建句子相似图之前识别并移除包含这些关键词的句子。
模式(正则表达式)过滤规则
电话号码:手机号码11位数或部分座机xxx-xxxx-xxx形式的号码。
phone_pattern = r'\d{3}[-.\s]?\d{3,4}[-.\s]?\d{4}'
网址:
website_pattern = r'\bhttp://[\.?#=\-\w+]+|(www[\.?#=\-\w+]+)|https://[\.?#=\-\w+]+'
通过正则表达式识别句子中的噪音模式,替换成待移除的token,在构建句子相似图前移除相关句子。
句子顺序问题
以其次、与此同时开头的句子被排在摘要的最前面

引入衰减因子优化句子权重
很多情况下,文章的具有一定的结构性,如”总——分“、”总——分——总“结构,最前面的句子往往比较重要。可以在textrank迭代过程中引入衰减函数,使越靠后的句子获得更低的重要性得分。可考虑使用以下衰减函数:
线性衰减
平方衰减
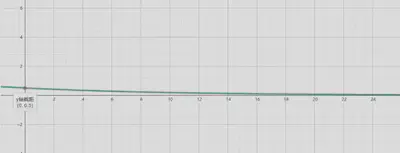
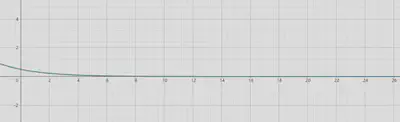
指数衰减
$f(x)=0.5 ℯ^{-0.1 x}$
$f(x)=0.5 ℯ^{-0.4 x}$

更多问题
图片类文章

需结合使用多模态或OCR的方法,纯文本方法无法解决。
视频类问题 有些文章具有视频,对于爬虫来说不能保证爬取到的网页源码再渲染后可重现视频内容。

考虑1:爬虫抽取正文文本时将视频视为噪音;(可能难有通用方案) 考虑2: 摘要提取前基于规则去除视频类html的干扰标签(简单可行)
广告无孔不入
一篇文章,超过一半篇幅都为广告内容:
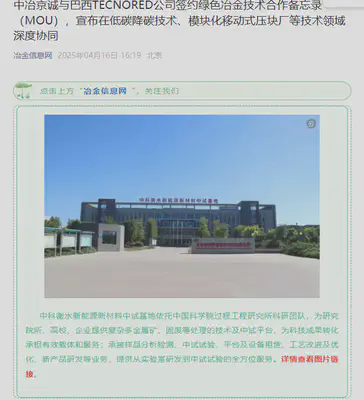
考虑:符号密度阈值(可行,但需要更多统计分析,泛化性难以通过理论证明)