爬虫框架Scrapy基本使用笔记
前期准备
开发环境
Pycharm
virtualenv
创建python虚拟环境(豆瓣源)
创建虚拟环境:
virtualenv -p PYTHON_PATH VITUAL_PAT; 激活虚拟环境:activate.bat; 退出虚拟环境:deactivate.bat管理虚拟环境的工具,windows系统下安装命令为
pip install virtualenvwrapper-win添加虚拟环境:
mkvirtualenv -p PYTHON.EXE WORK_PATH管理虚拟环境:
workon退出虚拟环境:
deactivate
MySQL
选择相应的版本,另行安装,否则安装scrapy可能出错,如“Failed building wheel for Twisted”
pypiwin32
windows环境下需要
pillow
使用pipeline读写图片文件需要。安装命令:
pip -i https://pypi.douban.com/simple pillow
基础知识
技术选型
- scrapy vs requests+beautifulsoup
scrapy框架基于twisted(异步IO特点),性能较高,scrapy内置的css、xpath selector,本身的功能足以完成beautifulsoup所有功能(bs4是纯python写出来的,scrapy相关功能是由C写的)
常见网页分类?
- 静态网页
- 动态网页
- webservice(restapi)
爬虫用武之地?
- 百度/谷歌类搜索引擎
- 垂直领域搜索引擎
- 推荐引擎: 今日头条
- 机器学习的数据样本
- 数据分析: 金融数据分析、舆情分析
爬虫分类
按目的分类
通用爬虫(baidu、google、……) 从网上爬取能检索到的网页并存储起来,对网页进行索引供用户搜索
聚焦爬虫 从网络中获取结构化数据
正则表达式
- 特殊字符
| 字符 | 意义 | 备注 |
|---|---|---|
| ^ | 起始字符 | |
| . | 任意字符 | |
| * | 出现多次 | |
| $ | 结尾字符 | |
| + | 出现至少一次 | |
| 非贪婪匹配 | ||
| {10} | 限定其前一字符出现频率为10 | |
| {10,} | 限定其前一字符出现频率为10次以上 | |
| {10,20} | 限定其前一字符出现频率为10到20次 | |
| pattern1|pattern2 | 匹配pattern1或pattern2,优先匹配前者 | |
| [2134] | 其中字符任选其一 | |
| [0-9] | 区间 | |
| [.*] | 中括号中的*和.只是单纯的字符 | |
| \s | ||
| \S | ||
| \w | ||
| \W | ||
| \d | 数字 | |
| [\u4E00-\u9FA5] | 汉字unicode编码 | |
| … | … |
- python api python有内置模块re用于正则表达式。
深度优先&&广度优先
网站的树结构 网站URl设计是分层的,绘制出URL层次结构图就得到了一棵“树”(一级域名、二级域名、…),针对“树”结构,常用策略就是深度优先和广度优先。但要注意URL环路
深度优先
递归
- 广度优先
利用队列
URL去重策略
将访问过的url保存到数据库中
效率较低
将访问过的url保存到set中,以o(1)的代价查询url 但爬虫通常涉及海量URL,URL长度也不定,用集合存储占用内存比较大
url经过md5等哈希方法后保存到set中
md5将任意长度的url映射到固定长度且不重复的字符串,但仍然占用内存较大
用bitmap方法,将访问过的url通过hash函数映射到某一位
冲突可能较高,将2个url映射到同一个位置。
bloomfilter 是对bitmap的改进,本质上是多重hash函数降低哈希冲突。原理上,布隆过滤器通过很长的二进制向量和映射函数检索一个元素是否在一个集合中。
key-value数据库
字符串编码
写文件、网络传输时常出现字符串编码相关的错误。采用sys.getdefaultencoding()可得环境默认字符串编码。Window Python3默认utf8,Python2默认ascii。Linux环境下又有所不同。
ASCII 美国标准编码,一个字节表示所有英文字符。
GB2312 两个字节表示一个汉字。Window环境下python默认gb2312编码。
将所有语言统一到一套编码,16 bit或32 bit囊括所有字符。如果内容全是英文时,unicode便会比ASCII需要多一倍+的存储空间,传输也需要更多时间。内存中读取文件采用unicode会较简单。
utf-8
可变长的编码。把英文表示为一个字节。汉字3个字节。特别生僻的汉字以4-6个字节表示,传输大量英文。文件保存/网络传输时采用utf8更有效率。
网络文件下载
urllib.request模块下的urlretrieve函数可用于下载远程服务器中的资源。
urlretrieve(url, filename=None, reporthook=None, data=None)
scrapy
github地址:https://github.com/scrapy/scrapy
安装
可直接使用pip进行安装:pip install -i https://pypi.douban.com/simple
开启征程
startproject即可建立scrapy项目,可选择模板、自定义模板
scrapy genspider --list
建立爬虫子任务命令:scrapy genspider SUB_TASK
指定模板创建爬虫任务:scrapy genspider -t TEMPLATE_NAME TASK_NAME DOMAIN,如
Spider调试
- pycharm debug
- scrapy shell 示例:
scrapy shell -s USER_AGENT="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36" https://www.lagou.com/jobs/5602462.html
xpath选择器
特点&&用途
可使用路径表达式在xml和html中进行导航;包含标准函数库;w3c标准
术语
| 术语 | 说明 | 备注 |
|---|---|---|
| 父节点 | ||
| 子节点 | ||
| 同胞节点 | ||
| 先辈节点 | ||
| 后代节点 |
- 语法
| 表达式 | 说明 | 备注 |
|---|---|---|
| article | 选取所有article元素的所有子节点 | |
| /article | 选取根元素article | |
| article/a | 选取所有属于article的子元素的a节点 | |
| //div | 选取文档中所有div元素 | |
| article//div | article下所有div元素 | |
| //@class | 选取所有名为class的属性 | |
| /article/div[1] | 属于article子元素的第一个div | |
| /article/div[last()] | 属于article子元素的最后一个div | |
| /article/div[last()-1] | ||
| //div[@lang] | 选择所有拥有lang属性的div元素 | |
| //div[@lang=‘eng’] | 选择所有lang属性为eng的div元素 | |
| /div/* | 选取所有属于div元素的所有子节点 | |
| //* | 选取所有元素 | |
| //div[@*] | 选取所有带属性的div元素 | |
| /div/a|//div/p | 选取所有div元素的a和p元素 | |
| //span|//ul | 选取文档中的span和ul元素 | |
| article/div/p|//span | 选取所有属于article元素的div元素的p元素和所有span元素 |
常用函数
- text()
- extract()
- extract_first()
- contains()
- strip()
- replace()
注意 选取xpath路径时,注意警惕ajax动态生成的标签,推荐使用chrome或firefox中copy xpath功能
css选择器
http://www.w3school.com.cn/cssref/css_selectors.ASP
- 语法
| 表达式 | 说明 | 备注 |
|---|---|---|
| .classname | 选取class为classname的元素 | |
| #idname | 选取id=idname的元素 | |
| div p | 选取div元素下的所有p子元素 | |
| div+p | 选取紧跟在div后的p | p和div是兄弟节点 |
| div>p | 选取div下第一个子元素p | |
| div,p | 选取所有名为class的属性 | |
| div#container>ul | 选择id=container的div元素后的第一个ul元素 | |
| ul~p | 选择与ul相邻的所有p元素 | |
| a[title] | 选择所有有title属性的a元素 | |
| a[href=“http://www.baidu.com”] | 选择href属性为http://www.baidu.com的a元素 | |
| a[href*=“baidu”] | 选择href属性中包含baidu的a元素 | |
| a[href^=“baidu”] | 选择href属性中以baidu开头的a元素 | |
| a[href$=“baidu”] | 选择href属性中以baidu结尾的a元素 | |
| input[type=radio]:checked | 选择所有处于选中状态的radio | |
| div:not(#container) | 选取所有id非container的div元素 | |
| li:nth-child(3) | 选取第三个li元素 | |
| tr:nth-child(2n) | 第偶数个tr |
session和cookie自动登录机制
理解模拟登陆和网站交互的基础。
cookie中包含着标识用户的信息,但还存在隐患,session用于解决此隐患:对用户信息(账号密码等)作一定处理生成session_data存放在服务端,而后返回给客户端一个可用于检索session_data的session_key作为cookie,并设置session过期时间。
- cookielib
- cookJar
- session
HTTP状态码
SEO优化需要了解,以免误导搜索引擎
- 200 请求被成功处理
- 301/302 永久性重定向/临时性重定向
- 403 没有权限访问
- 404 表示没有对应的资源。如遇到404页面,爬虫应不对其进行爬取
- 500 服务器错误
- 503 服务器停机或正在维护
selenium模拟
cmder
在windows下可使用部分linux命令 https://cmder.net/
实战1——爬取伯乐在线所有技术文章
需求分析
爬取所有技术文章的标题、正文、点赞数、评论数、发表时间、标签
爬取一篇文章的所需内容
实现翻页
寻找“下一页”的url
items设计
item即所要爬取的数据项,相当于数据需求
通过pipeline保存数据到mysql
pipeline拦截item,将拦截下的item保存到mysql即可
- python库
- codecs 与普通方式的区别在于文件编码
- ItemExporter
scrapy自带的item exporter,源码位于scrapy.exporters中,有各种类型的exporter

- 数据库设计 数据库表与item中内容一一对应
- 数据保存的mysql中
需要驱动如mysqlclient,如在ubuntu下还需要
sudo apt-get install libmysqlclient-dev,centos下需要sudo yum install python-devel mysql-devel,否则可能安装失败。 - 异步操作——MySQL连接池 上一步中插入mysql的方法有较大局限,scrapy解析速度大于数据库插入速度,所以可能会产生阻塞,采用twisted框架可较方便地实现MySQL插入异步化
scrapi item loader机制
提供一个容器方便模块化,方便后期维护item
常见错误
- ValueError:Missing scheme in request url:h
实战2——拉勾网职位信息爬取
Crawlspider剖析
https://docs.scrapy.org/en/latest/
需求分析及策略
以 https://www.lagou.com/jobs/5602462.html 为例,需要公司名称、招聘职位、薪资、工作城市、学历要求、工作经验要求、工作类型、职位诱惑、职位描述等数据
公司名称


招聘职位


工作要求


职位信息发布时间


标签


职位诱惑


职位描述

工作地址


Item Loader及数据入库
拉勾网目前会根据user-agent判断是否为爬虫,在chrome浏览器输入about:version可获得User-Agent信息。下面这个网站也可直接返回当前user-agent: https://helloacm.com/api/user-agent/
实战3–知嘟嘟专利爬虫
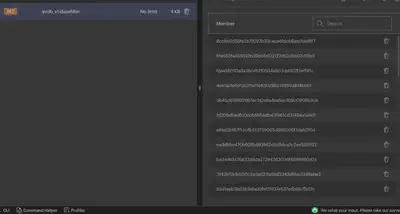
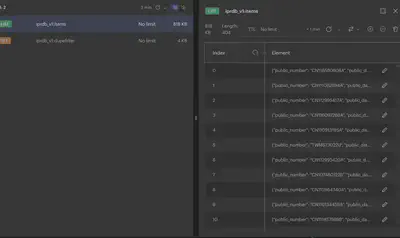
redis存储的中间结果:
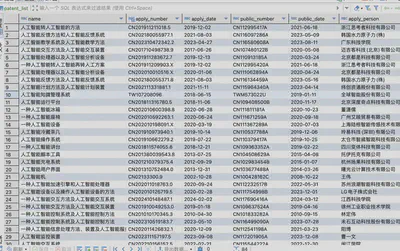
入库成果:

相关拓展
scrapy-redis
Redis可以作为scrapy的任务队列,对数据爬取任务进行去重和持久化,方便多进程/多节点协作的分布式爬虫。
相关配置示例:
# 启用调度
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 重复过滤
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
"scrapy_redis.pipelines.RedisPipeline": 400,
"iprdb.pipelines.PatentListPreprocessPipeline": 300,
}
REDIS_HOST = 'YOUR_IP_OR_DOMAIN'
REDIS_PORT = YOUR_PORT
REDIS_PARAMS = {
"password": "PASSWORD",
}
SCHEDULER_PERSIST = True
RFPDupeFilter 利用 Redis 的集合(set)数据类型来存储已经爬取的请求的指纹(即 URL 的某种哈希值)。当 Scrapy 爬虫尝试处理一个请求时,RFPDupeFilter 会计算该请求的指纹,并检查这个指纹是否已经存在于 Redis 集合中。如果指纹已存在,说明该请求已经被处理过,爬虫将不会再次爬取该 URL;如果指纹不存在,爬虫将继续处理请求,并将指纹添加到 Redis 集合中,以便将来的请求可以进行去重。