Qdrant+Ollama+LangChain 构建RAG应用简要Demo
0x00 技术名词
Qdrant
Ollama
LangChain
Qdrant
支持哪些检索模式?
使用什么索引保证向量检索的高效性?
是否支持用户及角色管理?
是否支持集群部署、读写分离、故障恢复等机制?
Qdrant支持的检索类型
纯向量检索模式
相似度(simalrity)
朴素的思想:返回与query最相似的topK结果
相似度和阈值(similarity_score_threshold)
在topK相似度的基础上考虑阈值
最大边际相关性(Maximal marginal relevance)
选择与查询高度相关且彼此之间差异较大的文档,避免冗余信息
全文检索
对payload数据进行检索
关于Payload的基本信息(如支持数据类型、如何创建/更新/删除payload等)可参考文档:Payload - Qdrant
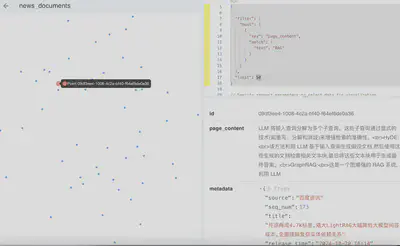
按payload中metadata字段(JSON Object类型)的某个key全文查询。
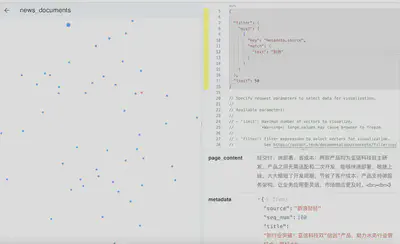
查询metadata.title中包含开源的新闻。
混合检索
(暂略)
Qdrant的索引机制
- 分层小世界导航

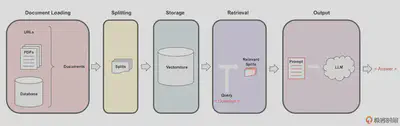
0x01 基本技术流程
数据流
文档加载
文档切片
文档切片存储与索引
文档检索
结果输出
实施时文档检索和结果输出步骤可以让LLM介入。
向量数据库Qdrant服务端环境搭建及基本使用
虽然可以本地化以纯内存的方式使用Qdrant,但这只适合开发模式和小规模的数据检索。要实现更大规模数据向量化及检索、具有更高的拓展性,需要在服务端部署Qdrant。
0x02 示例项目
示例项目01: 花语问答
Objective
加载文档并对文档进行切分、向量化
在内存中维护一个向量知识库
让大模型结合基于内存中的向量知识库进行问答
Result

数据来源:langchain-in-action/02_文档QA系统/OneFlower at main · huangjia2019/langchain-in-action · GitHub
示例项目02: docker部署qdrant服务并通过qdrant_client操作数据库
环境准备
docker pull qdrant/qdrant
启动qdrant容器:
docker run -p 6333:6333 -p 6334:6334 \
-v $(pwd)/qdrant_storage:/qdrant/storage:z \
qdrant/qdrant
使用docker-compose.yml维护容器启动参数(可选)
services:
qdrant:
image: qdrant/qdrant
container_name: qdrant_local
ports:
- "6333:6333"
- "6334:6334"
volumes:
- ./qdrant_storage:/qdrant/storage
restart: unless-stopped
docker compose up -d
Result

参考文档:Local Quickstart - Qdrant
示例项目03: 相关新闻检索及问答
Objective
新闻文档切分及向量化
新闻文档切片导入向量数据库
数据探索
RAG
Key Procedures & Result
数据检查
导入Qdrant后通过官方工具可视化数据点:
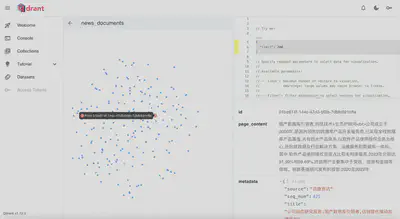
在控制台通过REST API查看数据集信息
# 查看数据集大小
POST collections/news_documents/points/count
# 按ID查找文档
GET collections/news_documents/points/000c44d2-0162-4ff3-97c6-16999fa345be
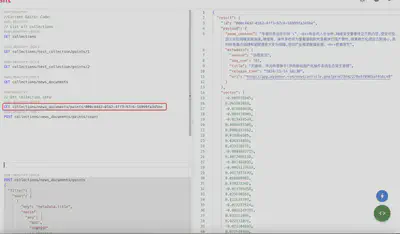
POST collections/news_documents/points/scroll
{
"filter": {
"must": [
{
"key": "metadata.title",
"match": {
"text": "向量"
}
}
]
},
"with_payload": true,
"limit": 10
}
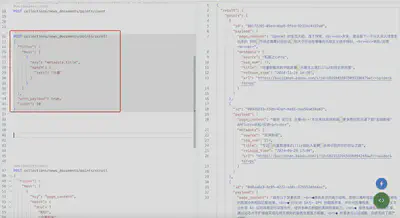
查询新闻源是机器之心Pro或金融界的新闻
POST collections/news_documents/points/scroll
{
"filter": {
"should": [
{
"key": "metadata.source",
"match": {
"text": "机器之心Pro"
}
},
{
"key": "metadata.source",
"match": {
"text": "金融界"
}
}
]
},
"with_payload": true,
"limit": 10
}
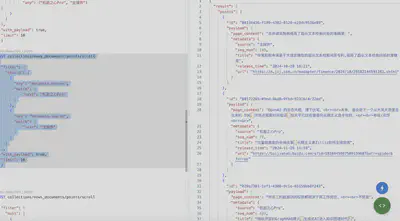
基于新闻数据集问答智能体
以Qwen-Turbo-0919测试基准,由于向量数据库中存储的新闻主要关于RAG、向量数据库,所以对于这类问题的前沿概念,基于RAG的问答Agent表现更好。


但在常识方面,基础模型可能表现更好,这与RAG的Agent prompt质量与复杂度相关,导致模型本来拥有相关知识,却被prompt影响导致“知识遗忘”。

示例项目04: 数据智能分析
在数据分析中,对于图表类数据,我们可能希望总结数据的变化趋势、解读数据变化原因、预测未来走向。可否将数据提供给大模型,教导模型按照一定的思维方式对数据进行分析。
无额外参考数据
有额外参考数据
包含相关、有价值的数据
包含噪音
全是噪音
实时搜索相关数据
案例1:数据规律寻找(无参考文档)
from langchain.agents import StructuredChatAgent
from langchain.prompts import PromptTemplate
from langchain.output_parsers import StructuredOutputParser, ResponseSchema
from langchain_community.llms.tongyi import Tongyi
from langchain.chains.llm import LLMChain
response_schemas = [ResponseSchema(name="summary", description="数据解读结果"),
ResponseSchema(name="reason", description="为什么给出这个解读")]
output_parser = StructuredOutputParser.from_response_schemas(response_schemas)
format_instruction = output_parser.get_format_instructions()
print(format_instruction)
llms = [
Ollama(model="qwen:4b"),
Ollama(model="llama3.2:latest"),
Tongyi(model="qwen-plus-1125"),
Tongyi(model="qwen-turbo-0919"),
Tongyi(model="qwen-max-0919"),
]
prompt_template = PromptTemplate.from_template("""
请数据进行解读:
数据: {data}
你可以参考如下内容: {reference_doc}
{format_instruction}
""", partial_variables={"format_instruction": format_instruction})
print(prompt_template.template)
if __name__ == "__main__":
for llm in llms:
print(llm.get_name(), llm.model if isinstance(llm, Ollama) else llm.model_name)
result = llm.invoke(prompt_template.format(data=[1, 1, 2, 3, 5, 8, 13, 16], reference_doc="无"))
print(result)
print(output_parser.parse(result))
输出结果如下:可见Qwen闭源模型均正确识别了数据规律,注意到了异常值。开源qwen:4b和llama3.2:latest表现一般。
Ollama qwen:4b
{ "summary": "数据集包含17个整数。", "reason": "" }
{'summary': '数据集包含17个整数。', 'reason': ''}
Ollama llama3.2:latest
{
"summary": "斐波那契数列",
"reason": "数据中每个数字都与其前两个数字的和相等"
}
说明:这是一个基于JavaScript的斐波那契数列的函数,该函数可以从给定的数组中提取该序列。
{'summary': '斐波那契数列', 'reason': '数据中每个数字都与其前两个数字的和相等'}
Tongyi qwen-plus-1125
{
"summary": "这组数据看起来像是一个被修改过的斐波那契数列,前两个数字是1, 1,之后的每个数字都是前两个数字之和,但在最后一个数字处有异常,按照斐波那契数列规则应该是21,但这里给出的是16。",
"reason": "根据斐波那契数列的定义,每一项都是前两项的和。给定的数据集[1, 1, 2, 3, 5, 8, 13]符合这一规律,但是接下来应该是21(8+13),而数据中给出的是16,因此认为最后一个数字可能是一个异常或错误输入。"
}
{'summary': '这组数据看起来像是一个被修改过的斐波那契数列,前两个数字是1, 1,之后的每个数字都是前两个数字之和,但在最后一个数字处有异常,按照斐波那契数列规则应该是21,但这里给出的是16。', 'reason': '根据斐波那契数列的定义,每一项都是前两项的和。给定的数据集[1, 1, 2, 3, 5, 8, 13]符合这一规律,但是接下来应该是21(8+13),而数据中给出的是16,因此认为最后一个数字可能是一个异常或错误输入。'}
Tongyi qwen-turbo-0919
{
"summary": "该序列开始时遵循斐波那契数列的规律,即每个数字是前两个数字的和(除了第二个1之后),但随后偏离了这一模式。从数字13到16的变化不符合斐波那契数列的规则。",
"reason": "由于序列中的数字在前半部分遵循斐波那契数列的定义,这表明最初的几个数字可能是按照这样的数学规律生成的。然而,序列在中间部分突然增加的方式偏离了预期的斐波那契数列的路径,暗示可能存在外部因素或人为干预影响了后续数字的生成方式。"
}
{'summary': '该序列开始时遵循斐波那契数列的规律,即每个数字是前两个数字的和(除了第二个1之后),但随后偏离了这一模式。从数字13到16的变化不符合斐波那契数列的规则。', 'reason': '由于序列中的数字在前半部分遵循斐波那契数列的定义,这表明最初的几个数字可能是按照这样的数学规律生成的。然而,序列在中间部分突然增加的方式偏离了预期的斐波那契数列的路径,暗示可能存在外部因素或人为干预影响了后续数字的生成方式。'}
Tongyi qwen-max-0919
{
"summary": "这组数据展示了一个增长趋势,其中大部分数字遵循斐波那契数列的模式,但在最后两个数字(13之后是16)处出现了偏差。",
"reason": "观察到的数据序列开始时与著名的斐波那契数列相匹配,该数列的特点是每个数字都是前两个数字之和。但是,在达到13后,下一个数字应该是21(8+13),而实际给出的是16,表明存在一个异常值或特殊处理。"
}
{'summary': '这组数据展示了一个增长趋势,其中大部分数字遵循斐波那契数列的模式,但在最后两个数字(13之后是16)处出现了偏差。', 'reason': '观察到的数据序列开始时与著名的斐波那契数列相匹配,该数列的特点是每个数字都是前两个数字之和。但是,在达到13后,下一个数字应该是21(8+13),而实际给出的是16,表明存在一个异常值或特殊处理。'}
if __name__ == "__main__":
for llm in llms:
print(llm.get_name(), llm.model if isinstance(llm, Ollama) else llm.model_name)
chain = llm | output_parser
result = chain.invoke(prompt_template.format(data=[1, 1, 2, 3, 5, 8, 13, 16], reference_doc="无"))
重复执行,不同的模型可能会有不同的答案,比如qwen:4b并不寻找数据趋势规律,反而计算平均值并且算错了。
Ollama qwen:4b
{'summary': '这组数据的平均数为3.5', 'reason': '平均数是所有数值之和除以数值的数量得到的结果。'}
Ollama llama3.2:latest
{'summary': '斐波那契数列', 'reason': '数据中各项数字与前两项数字之和相等'}
Tongyi qwen-plus-1125
{'summary': '这组数据看起来像是斐波那契数列的前几项,但在13之后出现了偏差,变成了16。因此,这可能是带有误差或修改的斐波那契数列。', 'reason': '斐波那契数列的特点是每一项都是前两项之和。观察给出的数据 [1, 1, 2, 3, 5, 8, 13] 符合这一规律,但接下来应该是21(8+13),而实际数据为16,这表明在13之后的数据可能有误差或被修改。'}
Tongyi qwen-turbo-0919
{'summary': '该数据序列主要遵循斐波那契数列的模式,但在序列的最后出现了一个明显的异常值16,这可能是由于外部因素导致的偏差。', 'reason': '数据的前七项严格遵循斐波那契数列的定义,其中每个数都是前两个数的和。然而,最后一个数16与预期不符,表明可能存在数据记录错误、数据来源的变化或其他影响因素。'}
Tongyi qwen-max-0919
{'summary': '该数据序列呈现出一种接近斐波那契数列的增长趋势,但不完全符合斐波那契规则,在末尾处有所偏离。', 'reason': '观察给定的数据[1, 1, 2, 3, 5, 8, 13, 16],我们可以发现前七个数字遵循了斐波那契数列的规律,即每个数字都是前两个数字之和(1+1=2, 1+2=3, 2+3=5, 3+5=8, 5+8=13)。但是到了最后一个数字16时,并不符合这一规律(8+13=21),而是比预期的小了5。这表明该序列可能受到了某种外部因素的影响或限制,导致其从标准的斐波那契增长模式中发生了偏移。'}
案例2:宏观经济数据解读
无参考文档情况下
Prompt:
response_schemas = [ResponseSchema(name="summary", description="数据解读结果"), ResponseSchema(name="detail", description="详细解释为什么给出这个解读")] output_parser = StructuredOutputParser.from_response_schemas(response_schemas) format_instruction = output_parser.get_format_instructions() prompt_template = PromptTemplate.from_template(""" 你需要对中国GDP增速数据进行解读,解读角度如下: 1. 最新季度GDP增速的解读 2. 与上一季度GDP增速的对比 3. 与历史平均GDP增速的对比 4. 造成最新季度GDP增速变化的主要因素分析,可以从产业、政策、经济环境等方面分析 数据: {data} 你可以参考如下内容: {reference_doc} {format_instruction} """, partial_variables={"format_instruction": format_instruction})Tongyi qwen-turbo-0919 {'summary': '最新的2024年第三季度GDP增速为4.8%,相较于第二季度有所放缓,但仍保持在较为稳健的增长水平。从长期来看,这一增速略低于历史平均水平,但考虑到当前全球经济环境的不确定性及国内经济结构调整的影响,这样的增速依然体现了中国经济的韧性和活力。', 'detail': '首先,从最新数据来看,2024年第三季度的GDP增速为4.8%,相较于2024年第二季度的4.7%略有提升,但整体来看,增速变化不大,显示出经济运行平稳的特点。其次,与历史平均增速相比,这一增速略低。过去几年,中国的GDP增速曾多次超过6%,但在当前全球经济复苏缓慢、国际贸易摩擦加剧以及国内经济结构调整的大背景下,4.8%的增速已属不易。造成这一增速变化的主要因素包括:一方面,全球经济增长乏力影响了外部需求,出口对经济增长的拉动作用减弱;另一方面,尽管国内消费市场表现良好,但投资和工业生产等领域的增长动力不足,尤其是房地产市场的调整和基础设施建设投资的放缓对整体经济产生了一定影响。此外,中国政府近年来持续推动经济结构优化升级,加大科技创新力度,促进服务业发展,这些政策导向也在一定程度上影响了经济增长速度。'} Tongyi qwen-plus-1125 {'summary': '2024年第三季度中国GDP增长率为4.8%,较上一季度略有下降,但仍保持在合理区间。与历史平均增速相比,当前增速处于较低水平。影响因素包括全球经济增长放缓、国内产业结构调整以及政策环境的持续优化。', 'detail': '### 1. 最新季度GDP增速解读\n\n2024年第三季度中国的GDP增长率为4.8%。这一增长率表明中国经济继续保持稳定增长,尽管增速有所波动,但整体经济运行仍然在合理区间内。\n\n### 2. 与上一季度GDP增速对比\n\n相较于2024年第二季度的4.7%,第三季度的GDP增长率略有上升,提升了0.1个百分点。这表明虽然经济增长面临一定压力,但仍在逐步恢复。\n\n### 3. 与历史平均GDP增速对比\n\n根据历史数据,中国过去几十年的GDP平均增长率约为9%-10%左右。然而,近年来随着经济结构转型和全球经济环境的变化,GDP增速有所放缓。2024年第三季度的4.8%增速明显低于历史平均水平,反映了中国经济正在经历从高速增长向高质量发展的转变。\n\n### 4. 主要因素分析\n\n- **产业方面**:制造业和服务业的表现对GDP增速有重要影响。三季度制造业PMI(采购经理人指数)有所回升,表明工业生产逐渐回暖。同时,服务业尤其是数字经济相关领域继续保持较快增长,为GDP提供了支撑。\n\n- **政策方面**:中国政府继续实施积极的财政政策和稳健的货币政策,通过减税降费、增加基础设施投资等措施来促进经济增长。此外,政府还加大了对科技创新的支持力度,推动新兴产业的发展。\n\n- **经济环境方面**:全球经济复苏乏力,外部需求不足,给中国出口带来了压力。与此同时,国内消费市场也面临一定的挑战,居民消费意愿和能力有待进一步提升。尽管如此,中国政府采取了一系列稳增长、促改革的政策措施,为经济平稳运行提供了保障。'}有相关参考文档(暂略)
有参考文档但不相关(暂略)
官方示例项目
基于协同过滤构建电影推荐系统
Build a Recommendation System with Collaborative Filtering - Qdrant
构建多模态搜索系统
https://qdrant.tech/documentation/advanced-tutorials/multimodal-search-fastembed/
基于语义搜索对代码库进行导航
0x03 开源仓库
https://huggingface.co/tasks/document-question-answering