Python核心编程-多线程编程(代码篇)
常用代码片段示例
前言
本篇短文基于Python核心编程第四章,通过代码示例总结python多线程的用法、相关概念、数据结构、注意事项。内容要点如下:
- 进程和线程的区别是什么?
- Python如何实现多线程?
- Python中的线程特性
- Python中如何保证线程安全?
- 多线程相关经典的数据结构设计思路?
概念
进程与线程的关系与区别
根据ChatGPT3.5给出的回复:
进程(Process)与线程(Thread)是操作系统中两个重要的概念,它们在计算机系统中扮演着不同的角色。
1. 定义:
- 进程:进程是操作系统中的一个执行单位,可以理解为正在运行的程序的实例。它包含了程序代码、数据集、打开的文件、正在执行的线程等。
- 线程:线程是进程中的一个执行流程,是CPU调度和执行的基本单位。一个进程中可以包含多个线程,它们共享相同的地址空间和资源,可以同时执行多个任务。
2. 资源和隔离:
- 进程:进程拥有独立的地址空间和资源(如内存、文件句柄等),不同进程之间的数据通信需要使用特定的机制(如管道、消息队列等),进程间相互隔离。
- 线程:线程是在进程内部创建的,它们共享相同的地址空间和资源,可以直接访问进程中的变量和数据,线程间通信更加简单高效。
3. 调度和切换:
- 进程:进程切换需要保存和恢复较多的上下文信息,包括程序计数器、寄存器、内存映射表等,切换开销较大。进程调度由操作系统负责,决定何时切换进程。
- 线程:由于线程共享进程的资源,线程切换的开销较小,只需要保存和恢复线程特定的上下文。线程调度由操作系统内核的线程调度器负责,决定何时切换线程。
4. 并发性和效率:
- 进程:由于进程间的隔离性,进程的并发性较低,进程之间的通信和同步需要使用复杂的机制。由于进程切换的开销较大,进程间的切换频率较低,效率较低。
- 线程:由于线程共享资源,线程之间的通信和同步更加方便快捷。由于线程切换开销小,线程之间的切换频率可以较高,效率较高。
总之,进程和线程在操作系统中扮演着不同的角色。进程是一个独立的执行单元,拥有独立的资源和隔离性;而线程是进程的子执行单元,共享地址空间和资源,更加轻量级和高效。
简单来说,进程是操作系统资源分配的最小单位,而线程是CPU调度的最小单位,因此一个进程中至少有一个线程才能利用CPU进行计算,而同一个进程中的多个线程共享进程的资源,可以说进程是线程的容器,线程是真正的“打工人”。也正是因此,进程的创建和销毁要比线程的创建和销毁造成更大的系统开销,因为每次创建/销毁进程都需要重新分配/释放资源。
代码解析
本节汇总Python核心编程第四章-多线程编程中部分实例代码的Python3实现(或许经过一定的调整,因为书中部分示例代码已经过时无法正常工作或使用python2实现)。
基于thread(Python3的低级线程模块)进行多线程任务
thread模块提供了start_new_thread方法用于派生新线程,start_new_thread包含两个参数,函数对象和函数参数。
# mtsleepA.py
"""
核心编程不建议使用_thread模块(thread),原因如下:
1. _thread不支持守护线程的概念;
2. thread模块只有一个同步原语;
3. 对于进程何时退出没有控制,主线程退出时所有子线程都会终止
"""
import _thread
from time import sleep, ctime
def loop0():
print(f"start loop 0 at:{ctime()}")
sleep(4)
print(f"loop 0 done at {ctime()}")
def loop1():
print(f"start loop1 at {ctime()}")
sleep(2)
print(f"loop 1 done at {ctime()}")
def main():
print(f"starting at {ctime()}")
_thread.start_new_thread(loop0, ())
_thread.start_new_thread(loop1, ())
sleep(6)
print(f"all done at {ctime()}")
if __name__ == "__main__":
main()

使用thread模块的锁对象控制代码执行逻辑
使用_thread.allocate_lock()方法可以获得一个锁对象(LockType), LockType具有以下方法:
| 方法 | 描述 | 备注 |
|---|---|---|
| acquire() | 尝试获取锁对象 | |
| locked() | 判断是否获取了锁对象,若获取返回True,否则返回False | |
| release() | 释放锁 |
# mtsleepB.py
"""
用一个函数完成多个线程的循环,根据参数不同决定行为不同
"""
import _thread
from time import sleep, ctime
loops = [4, 2]
def loop(nloop: str, sec: int, lock: _thread.LockType):
print(f"loop {nloop} start at {ctime()}")
sleep(sec)
print(f"loop {nloop} done at {ctime()}")
# 释放锁,lock必须是锁定状态才可调用release()方法,否则会抛出异常
lock.release()
def main():
print(f"start at {ctime()}")
locks = []
for i in range(len(loops)):
# 获取锁对象
lock = _thread.allocate_lock()
# 上锁
lock.acquire()
locks.append(lock)
for i in range(len(loops)):
# 启动新线程并为每个线程分配一个锁
_thread.start_new_thread(loop, (i, loops[i], locks[i]))
for i in range(len(loops)):
# 等待所有锁释放
while locks[i].locked():
pass
# 只有当所有子线程执行完毕(释放锁),该代码块才会执行下去
print(f"all done at {ctime()}")
if __name__ == "__main__":
main()
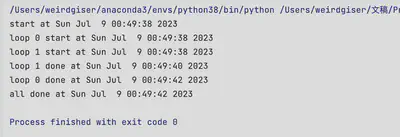
基于高级线程模块threading进行多线程编程
threading模块对_thread模块进行了封装,提供更高级别、功能更全面的线程管理。比如,threading支持更多同步原语(Condition、Semaphore等),支持守护线程,能够控制主线程退出时是否需要等待某些子线程完成。(默认情况下,threading创建的子线程是非守护线程,在线程启动前执行thread.daemon=True赋值语句可以让该线程以守护线程方式启动,把线程设置为守护线程后,进程(Python解释器)的退出不会等待守护线程完成工作;而对于非守护线程,进程的退出需要等待所有非守护线程完成。
创建Thread类的实例
实例化一个Thread类,将需要新线程执行的函数及参数传递给Thread类,通过实例化对象的start方法启动线程。
# mtsleepC.py
import threading
from time import ctime, sleep
loops = [4,2]
def loop(nloop, sec):
print(f"loop {nloop} start at {ctime()}")
sleep(sec)
print(f"loop {nloop} done at {ctime()}")
def main():
print(f"starting at {ctime()}")
threads = []
# 创建线程类
nthreads = len(loops)
for i in range(nthreads):
# 创建Thread类实例,线程不会立刻开始执行
t = threading.Thread(target=loop, args=(i, loops[i]))
threads.append(t)
# 执行线程
for t in threads:
t.start()
# 等待所有线程完成
for t in threads:
t.join()
print(f"all done at {ctime()}")
if __name__ == "__main__":
main()

创建Thread的实例并传给它一个可调用的类ThreadFunc实例
创建新线程时,Thread类的代码会调用ThreadFunc对象,执行其__call__方法。
# mtsleepD.py
"""使用可调用的类执行线程"""
from time import sleep, ctime
import threading
loops = [4,2]
class ThreadFunc:
"""可调用的类对象"""
def __init__(self, func, args, name=""):
self.func = func
self.args = args
self.name = name
def __call__(self):
self.func(*self.args)
def loop(nloop, sec):
print(f"start loop {nloop} at {ctime()}")
sleep(sec)
print(f"loop {nloop} done at {ctime()}")
def main():
print(f"starting at {ctime()}")
threads = []
nthreads = len(loops)
for i in range(nthreads):
t = threading.Thread(target=ThreadFunc(loop, (i, loops[i]), loop.__name__))
threads.append(t)
for t in threads:
t.start()
for t in threads:
t.join()
if __name__ == "__main__":
main()
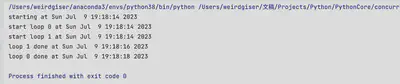
派生Thread的子类并创建子类的实例
# mysleepE.py
"""Thread子类化:派生Thread的子类,并创建类的实例"""
import threading
from time import sleep, ctime
loops = [4,2]
class MyThread(threading.Thread):
def __init__(self, func, args, name=""):
threading.Thread.__init__(self)
self.name = name
self.func = func
self.args = args
def run(self):
self.func(*self.args)
def loop(nloop, sec):
print(f"loop {nloop} start at {ctime()}")
sleep(sec)
print(f"loop {nloop} done at {ctime()}")
def main():
print(f"starting at {ctime()}")
nthreads = len(loops)
threads = []
for i in range(nthreads):
t = MyThread(loop, (i, loops[i]), loop.__name__)
threads.append(t)
for t in threads:
t.start()
for t in threads:
t.join()
print(f"all done at {ctime()}")
if __name__ == "__main__":
main()

将MyThread类抽取出来,封装在myThread.py中
# myThread.py
import threading
from time import sleep, ctime
loops = [4,2]
class MyThread(threading.Thread):
def __init__(self, func, args, name=""):
threading.Thread.__init__(self)
self.res = None
self.name = name
self.func = func
self.args = args
def run(self):
print(f"thread {self.name} start at {ctime()}")
self.res = self.func(*self.args)
print(f"thread {self.name} done at {ctime()}")
def get_result(self):
return self.res
单线程和多线程执行对比
# mtfacfib.py
from concurrent_.multithread_demo.myThread import MyThread
from time import sleep, ctime
def fib(x):
sleep(0.005)
if x<=2:
return 1
return fib(x-2)+fib(x-1)
def fac(x):
sleep(0.1)
if x<2:
return 1
return x*fac(x-1)
def sum(x):
sleep(0.1)
if x<2:
return 1
return x+sum(x-1)
funcs = [fib, fac, sum]
n = 20
def main():
threads = []
nfuncs = len(funcs)
print(f"Single Thread")
for i in range(nfuncs):
print(f"{funcs[i].__name__} start at {ctime()}")
print(funcs[i](n))
print(f"{funcs[i].__name__} done at {ctime()}")
print("\n Multiple Thread")
for i in range(nfuncs):
t = MyThread(funcs[i], (n, ), funcs[i].__name__)
threads.append(t)
for t in threads:
t.start()
for t in threads:
t.join()
print(t.get_result())
print(f"all done at {ctime()}")
if __name__ == "__main__":
main()

图书排名示例
核心编程4.7节给出了一个获取亚马逊图书排名的示例,给定isbn号,从亚马逊网页中搜索相关图书并从网页源码中解析出图书排名。须注意:书中示例使用urlopen方法直接请求图书网页,截止目前该方法已失效,包括使用简单的requests.get,更改user-agent都无法成功获取数据,而是会收到亚马逊服务器返回的以下提示(被识别为爬虫了):

目前,通过selenium库使用chrome浏览器驱动附带cookie的请求能够使得图书排名获取功能正常工作。
# bookrank.py
from atexit import register
from re import compile
from threading import Thread
import selenium
from selenium.webdriver import Chrome, ChromeOptions
from time import ctime
from urllib.request import urlopen as uopen
import requests
REGEX = compile("#([\d,]+) in Books ")
options = ChromeOptions()
options.headless = True
USERAGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36"
options.add_argument('--user-agent=%s' % USERAGENT)
CHROME_DRIVER_PATH = r"E:\webdriver\chromedriver_win32\chromedriver.exe"
BROWSER = Chrome(executable_path=CHROME_DRIVER_PATH, options=options)
AMZN = "http://amazon.com/dp/"
ISBNs = {
"0132269937": "Core Python Programming",
"0132356139": "Python Web Development with Django",
"0137143419": "Python Fundamentals"
}
# 2023.07.05, Amazon进行了反爬虫限制,无法在程序中通过简单的get请求获取页面内容
# 需要添加在请求中包含cookie信息
def getRanking(isbn):
# page = uopen(f"{AMZN}{isbn}")
# data = page.read()
# page.close()
headers = {'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36",
"Accept-Language":"zh-CN,zh;q=0.9"}
# 预请求:初始化cookie结构
BROWSER.get(url=f"{AMZN}{isbn}")
# 该cookie不通用,也可能随时间变化
BROWSER.add_cookie({"name": "session-id", "value":"140-8014858-6609201"})
BROWSER.add_cookie({"name":"i18n-prefs", "value":"USD"})
BROWSER.add_cookie({"name":"session-token", "value":"tLEwYzFlUQuOjNjyYnPucZgkNMkmJcfQtDRm2DESOxu/heCXmkeXUqyz46mjk2+bGe7riDb4ZNzhSTwEDHKNCCYETi4bcuhS7ldviz9/bgGXpSV3hLtM54O6ZYG/3XPwnrdwd5hE3NZ3N7xxDkhMEdYh/wIz4YAc9yyiSO782v8mFlvS1ALpIuWxPiFeyWnUum/xDPSRV02QMBaNhnVMPhNcVDFXxt7e3jZ3G3kZJwc="})
BROWSER.get(url=f"{AMZN}{isbn}")
return REGEX.findall(BROWSER.page_source)[0]
def _showRanking(isbn):
print(f"processing {isbn}")
print(f"- {ISBNs[isbn]}, {getRanking(isbn)}")
def main():
print(f"Start at {ctime()} on Amazon.")
for isbn in ISBNs:
_showRanking(isbn)
@register
def _atexit():
print(f"all DONE at {ctime()}")
if __name__ == "__main__":
main()

引入多线程后:
# bookrank_multithread.py
from atexit import register
from re import compile
from threading import Thread
from selenium.webdriver import Chrome, ChromeOptions
from time import ctime
REGEX = compile("#([\d,]+) in Books ")
options = ChromeOptions()
options.headless = True
USERAGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36"
options.add_argument('--user-agent=%s' % USERAGENT)
CHROME_DRIVER_PATH = r"E:\webdriver\chromedriver_win32\chromedriver.exe"
BROWSER = Chrome(executable_path=CHROME_DRIVER_PATH, options=options)
AMZN = "http://amazon.com/dp/"
ISBNs = {
"0132269937": "Core Python Programming",
"0132356139": "Python Web Development with Django",
"0137143419": "Python Fundamentals"
}
# 2023.07.05, Amazon进行了反爬虫限制,无法在程序中通过简单的get请求获取页面内容
#
def getRanking(isbn):
# page = uopen(f"{AMZN}{isbn}")
# data = page.read()
# page.close()
headers = {'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36",
"Accept-Language":"zh-CN,zh;q=0.9"}
#
# page = requests.get(f"{AMZN}{isbn}",headers=headers)
# data = page.text
# page.close()
# BROWSER.add_cookie({"Cookie":'session-id=140-8014858-6609201; session-id-time=2082787201l; i18n-prefs=USD; lc-main=en_US; sp-cdn="L5Z9:CN"; ubid-main=130-2583056-8326113; skin=noskin; session-token="tLEwYzFlUQuOjNjyYnPucZgkNMkmJcfQtDRm2DESOxu/heCXmkeXUqyz46mjk2+bGe7riDb4ZNzhSTwEDHKNCCYETi4bcuhS7ldviz9/bgGXpSV3hLtM54O6ZYG/3XPwnrdwd5hE3NZ3N7xxDkhMEdYh/wIz4YAc9yyiSO782v8mFlvS1ALpIuWxPiFeyWnUum/xDPSRV02QMBaNhnVMPhNcVDFXxt7e3jZ3G3kZJwc="'})
# 预请求一次
# 否则selenium.common.exceptions.InvalidCookieDomainException: Message: invalid cookie domain
BROWSER.get(url=f"{AMZN}{isbn}")
print("old cookie", BROWSER.get_cookies())
BROWSER.add_cookie({"name": "session-id", "value":"140-8014858-6609201"})
BROWSER.add_cookie({"name":"i18n-prefs", "value":"USD"})
BROWSER.add_cookie({"name":"session-token", "value":"tLEwYzFlUQuOjNjyYnPucZgkNMkmJcfQtDRm2DESOxu/heCXmkeXUqyz46mjk2+bGe7riDb4ZNzhSTwEDHKNCCYETi4bcuhS7ldviz9/bgGXpSV3hLtM54O6ZYG/3XPwnrdwd5hE3NZ3N7xxDkhMEdYh/wIz4YAc9yyiSO782v8mFlvS1ALpIuWxPiFeyWnUum/xDPSRV02QMBaNhnVMPhNcVDFXxt7e3jZ3G3kZJwc="})
print("new cookies", BROWSER.get_cookies())
BROWSER.get(url=f"{AMZN}{isbn}")
return REGEX.findall(BROWSER.page_source)[0]
def _showRanking(isbn):
print(f"processing {isbn}")
print(f"- {ISBNs[isbn]}, {getRanking(isbn)}")
print(f" {isbn} done at {ctime()}")
def main():
print(f"Start at {ctime()} on Amazon.")
threads = []
for isbn in ISBNs:
t = Thread(target=_showRanking, args=(isbn,), name=isbn)
threads.append(t)
for t in threads:
t.start()
for t in threads:
t.join()
@register
def _atexit():
print(f"all DONE at {ctime()}")
if __name__ == "__main__":
main()

可以看到,在此例中,相比于单线程版本(1min53s),多线程版本要稍快一些(1min27s),因为这是一个I/O密集型应用。
使用同步原语避免竞态条件,保证多线程数据同步安全
锁的示例
不使用锁的多线程代码示例
# mtsleepF.py
import atexit
from atexit import register
from random import randrange
from time import ctime, sleep
from threading import Thread, currentThread
class CleanOutputSet(set):
def __str__(self):
return ",".join(x for x in self)
loops = (randrange(2,5) for x in range(randrange(3,7)))
remaining = CleanOutputSet()
def loop(nsec):
myname = currentThread().name
remaining.add(myname)
print(f"[{ctime()}] Started {myname}")
sleep(nsec)
remaining.remove(myname)
print(f"[{ctime()} Completed {myname} ({nsec} secs)]")
print(f"remaining {remaining or 'None'}")
def main():
for pause in loops:
Thread(target=loop, args=(pause, )).start()
@atexit.register
def _atexit():
print(f"all done at: {ctime()}")
if __name__ == "__main__":
main()

使用锁阻塞线程访问某一代码块
# mtsleepF_lock.py
import atexit
import threading
from random import randrange
from time import ctime, sleep
from threading import Thread, currentThread, Lock
lock = Lock()
class CleanOutputSet(set):
def __str__(self):
return ",".join(x for x in self)
loops = (randrange(2,5) for x in range(randrange(3,7)))
remaining = CleanOutputSet()
def loop(nsec):
myname = currentThread().name
lock.acquire()
remaining.add(myname)
print(f"[{ctime()}] Started {myname}")
lock.release()
sleep(nsec)
lock.acquire()
remaining.remove(myname)
print(f"[{ctime()} Completed {myname} ({nsec} secs)]")
print(f"remaining {remaining or 'None'}")
print(f"current: {threading.enumerate()}")
lock.release()
def main():
for pause in loops:
Thread(target=loop, args=(pause, )).start()
@atexit.register
def _atexit():
print(f"all done at: {ctime()}")
if __name__ == "__main__":
main()

通过上下文管理器语法(with)使用锁对象
threading模块的Lock、RLock、Condition、Semaphore和BoundedSemaphore都包含上下文管理器,可以通过with语句使用,简化锁对象使用的代码块。
# mtsleepF_withlock.py
import atexit
import sys
from random import randrange
from time import ctime, sleep
from threading import Thread, currentThread, Lock
lock = Lock()
class CleanOutputSet(set):
def __str__(self):
return ",".join(x for x in self)
loops = (randrange(2,5) for x in range(randrange(3,7)))
remaining = CleanOutputSet()
def loop(nsec):
myname = currentThread().name
# 通过上下文管理器使用锁,简化代码
with lock:
remaining.add(myname)
print(f"[{ctime()}] Started {myname}")
sleep(nsec)
with lock:
remaining.remove(myname)
print(f"[{ctime()} Completed {myname} ({nsec} secs)]")
print(f"remaining {remaining or 'None'}")
# print(f"current: {threading.enumerate()}")
def main():
threads = []
for pause in loops:
t = Thread(target=loop, args=(pause,))
threads.append(t)
t.start()
print(f"test main {ctime()}")
# 为什么没有join,主线程也会等待子线程执行完毕
# for t in threads:
# t.join()
@atexit.register
def _atexit():
print(f"all done at: {ctime()}")
if __name__ == "__main__":
main()

信号量示例
如果我们的多线程程序的行为需要根据某些资源(共享资源)的可用与否进行变化,如资源不可用时限制线程对共享资源的获取。信号量是一个可以表示资源计数的同步原语,当有线程消耗资源会使得信号量的计数器递减,增加资源则会使得信号量的计数器递增。
candy.py例子演示了信号量对象BoundedSemaphore的使用,只有信号量大于0时(意味着售货机有货物可出售),客户端才可以购买商品(调用buy方法);当信号量为MAX时(意味着售货机货物已满),服务方不能为售货机补充货物(调用refill方法)。
# candy.py
"""糖果机和信号量
模拟场景:售货机最多只能有N件商品同时在售
有生产者和消费者不定期对售货机的商品进行补充或购买
如果售货机商品已满,生产者无法对其进行补充;
如果售货机无商品,消费者无法购买
BoundedSemaphore: 信号量类,可确保计数器的值不会超过预设的初始值
"""
import atexit
from threading import Thread, Lock, BoundedSemaphore
from atexit import register
from random import randrange
from time import sleep, ctime
lock = Lock()
MAX = 5
candytray = BoundedSemaphore(MAX)
def refill():
"""
注入商品
:return:
"""
lock.acquire()
print("filling candy tray")
try:
# candytray._value += 1
candytray.release()
except ValueError as e:
print("full, skipping.")
else:
print("OK")
lock.release()
def buy():
lock.acquire()
print("Buy candy...")
# 非阻塞获取,如果获取失败则返回False
if candytray.acquire(blocking=False):
print("OK")
else:
print("Empty, skipping...")
lock.release()
def producer(nloops):
for i in range(nloops):
refill()
sleep(randrange(3))
def comsumer(nloops):
for i in range(nloops):
buy()
sleep(randrange(3))
def main():
print(f"Starting at {ctime()}")
nloops = randrange(2, 6)
print(f"Candy machine full with {MAX}")
Thread(target=comsumer, args=(nloops + MAX,)).start()
Thread(target=producer, args=(nloops,)).start()
@atexit.register
def _atexit():
print(f"All done at {ctime()}")
if __name__ == "__main__":
main()

生产者-消费者问题与Queue/queue模块
Python2中的Queue模块(在python3.x中被重命名为queue)封装了并发安全的队列类,如Queue、LifoQueue、PriorityQueue等。
下例基于Queue实现简易的生产者-消费者模型
# prodcons.py
"""生产者消费者模型
基于Queue队列实现生产者消费者模型
"""
from random import randint
from time import sleep, ctime
from queue import Queue
from myThread import MyThread
def writeQ(queue:Queue):
print(f"write queue starting at {ctime()}")
# put方法会阻塞直到queue有数据
queue.put(1)
print(f"write queue done at {ctime()}, currently queue size: {queue.qsize()}")
def readQ(queue: Queue):
print(f"read queue starting at {ctime()}")
if queue.empty():
print("try to read queue, but queue is empty")
else:
# get_nowait()为非阻塞调用,相当于get(block=False)
print(queue.get_nowait())
print(f"read queue done at {ctime()}, currently queue size: {queue.qsize()}")
def writer(queue, nloops):
for i in range(nloops+3):
writeQ(queue)
sleep(randint(1, 2))
def reader(queue, nloops):
for _ in range(nloops):
readQ(queue)
sleep(randint(6,20))
funcs = [reader,writer]
nfuncs = len(funcs)
def main():
nloops = randint(8,15)
print(f"initializing {nloops}")
q = Queue(10)
threads = []
for i in range(nfuncs):
t = MyThread(func=funcs[i], args=(q, nloops), name=funcs[i].__name__)
threads.append(t)
for t in threads:
t.start()
for t in threads:
t.join()
print(f"all done at {ctime()}")
if __name__ == "__main__":
main()

多线程相关模块
底层多线程API
基于_thread模块提供更易用的高级多线程API
基于进程的并行库。
multiprocessing包同时提供了本地和远程并发操作,通过使用子进程而非线程有效地绕过了 全局解释器锁。 因此,multiprocessing模块允许程序员充分利用给定机器上的多个处理器完全跳过线程,生成新的进程,连接新进程的输入、输出、错误管道,并获取其返回码。
queue
供多线程使用的同步安全的队列模块
mutex
互斥对象。自Python2.6起不建议使用,并在Python3.0移除。
concurrent.futures
异步执行的高级别库
SocketServer
创建/管理线程控制的TCP/UDP服务器
小结:在CPython存在全局解释器锁,同一时刻只有一个线程可以执行Python代码。如果想要更好地利用多核计算机的计算资源,推荐使用multiprocessing或concurrent.futures.ProcessPoolExecutor。但是,如果你想要同时运行多个 I/O 密集型任务,则多线程仍然是一个合适的模型。
多线程编程练习/数据结构
线程和文件
问题:a) 创建一个函数,给定一个字节值和一个文件名,然后显示文件中该字节出现的次数; b) 假设输入文件非常大。尝试创建多个线程使每个线程负责文件某一部分的计数最后将每个线程的数据进行整合; c) 假设输入文件非常大。尝试创建多个进程使每个进程负责文件某一部分的计数最后将每个进程的数据进行整合。
问题a实现
初始化一个计数值(0),读取文件,循环读一个字节并判断该字节是否等于给定字节,若相等则使计数值增加1,直到文件内容全部读完,返回计数值。
# 4.4-a
import time
import timeit
from time import ctime
def show_byte_count(byte_var, filename):
"""给定一个字节值和文件名,展示文件中某字节出现的次数"""
count = 0
with open(filename, 'rb') as f:
while True:
# 如果无数据,读出的是空字节b''
var = f.read(1)
if var == byte_var:
count += 1
if not var:
break
return count
if __name__ == "__main__":
start_time = time.time()
print(f"starting at {start_time}")
print(show_byte_count(b"p", "test1.txt"))
end_time = time.time()
print(f"all done at {end_time}, cost: {(end_time-start_time)*1000}")
对大文件test1.txt的计数结果如下:
问题b实现
相比于问题a,多线程版本读取文件的关键在于“划分任务”和“汇总结果”:如何将一个文件的字节计数问题拆分为若干个小任务并交予多个线程执行,并最终汇总结果。
# multithreads and file
import logging
import os
import argparse
import time
from threading import Lock, Thread
lock = Lock()
result = 0
def get_file_size(path):
return os.stat(path).st_size
def calc_byte_count(filepath, byte_var, begin_pos, end_pos):
global result
with open(filepath, "rb") as f:
count = 0
f.seek(begin_pos)
for _ in range(begin_pos, end_pos):
var = f.read(1)
if byte_var == var:
count += 1
lock.acquire()
result += count
lock.release()
def main(**kwargs):
num_thread = kwargs.pop("num_thread", 4)
file_path = kwargs.pop("file_path", None)
byte_value = kwargs.pop("byte_value", None)
if not isinstance(byte_value, bytes):
raise TypeError("byte_value should be bytes type")
if not os.path.exists(file_path):
raise ValueError(f"file {file_path} not exist!")
file_size = get_file_size(file_path)
# 判断线程数是否超标
if num_thread > file_size:
logging.warning("num_thread exceed file_size.")
num_thread = file_size
# 将文件字节按线程数划分为若干个并行任务:每个线程应该处理的字节数
byte_per_thread = file_size // num_thread
extra_byte = file_size % num_thread
threads = []
cursor_ranges = []
start_pos = 0
for _ in range(num_thread):
cursor_ranges.append([start_pos, start_pos+byte_per_thread])
start_pos = start_pos+byte_per_thread
cursor_ranges[-1][-1] = cursor_ranges[-1][-1]+extra_byte
# print(cursor_ranges)
for cursor_range in cursor_ranges:
t = Thread(target=calc_byte_count, args=(file_path, byte_value, cursor_range[0], cursor_range[1]))
threads.append(t)
for t in threads:
t.start()
for t in threads:
t.join()
print("result:", result)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--num_thread", dest="num_thread", type=int, default=10, help="number of threads")
parser.add_argument("--file_path", dest="file_path", default="test1.txt", help="path of file")
parser.add_argument("--byte_var", dest="byte_var", default=b"p", help="byte value")
args = parser.parse_args()
num_thread = args.num_thread
file_path = args.file_path
byte_var = args.byte_var
start_time = time.time()
print(f"starting at {start_time}")
main(num_thread=num_thread, file_path=file_path, byte_value=byte_var)
end_time = time.time()
print(f"all done at {end_time}, cost: {(end_time-start_time)*1000}")
多线程(以10个线程为例)读取文件并计数的结果如下,可见10线程反而比单线程慢(个人测试时无论是对大文件还是小文件进行计数,多线程一定比单线程慢)。
问题c实现
相比于多线程实现文件计数,多进程版本需要注意的是多进程间共享变量的使用。多线程版本中我们可以通过一个全局变量result来汇总各个线程的计数结果,但这个方法默认情况下在多进程环境下行不通,因为每个进程都会产生一个result的副本。要将多进程的结果通过共享内存中的变量汇总,需要用到multiprocessing库中的Value(或Array,但这个例子只用Value)
# multiprocess and file
import logging
import os
import argparse
import time
from multiprocessing import Lock, Process, Value
mylock = Lock()
result = Value("i", 0)
def get_file_size(path):
# print(os.path.getsize("test.txt"))
# print(os.stat("test.txt"))
return os.stat(path).st_size
def calc_byte_count(filepath, byte_var, begin_pos, end_pos, lock, result):
# global result
with open(filepath, "rb") as f:
count = 0
f.seek(begin_pos)
for _ in range(begin_pos, end_pos):
var = f.read(1)
if byte_var == var:
count += 1
lock.acquire()
result.value += count
lock.release()
def main(**kwargs):
num_thread = kwargs.pop("num_thread", 4)
file_path = kwargs.pop("file_path", None)
byte_value = kwargs.pop("byte_value", None)
if not isinstance(byte_value, bytes):
raise TypeError("byte_value should be bytes type")
if not os.path.exists(file_path):
raise ValueError(f"file {file_path} not exist!")
file_size = get_file_size(file_path)
# 判断线程数是否超标
if num_thread > file_size:
logging.warning("num_thread exceed file_size.")
num_thread = file_size
# 将文件字节按线程数划分为若干个并行任务:每个线程应该处理的字节数
byte_per_thread = file_size // num_thread
extra_byte = file_size % num_thread
processes = []
cursor_ranges = []
start_pos = 0
for _ in range(num_thread):
cursor_ranges.append([start_pos, start_pos+byte_per_thread])
start_pos = start_pos+byte_per_thread
cursor_ranges[-1][-1] = cursor_ranges[-1][-1]+extra_byte
# print(cursor_ranges)
for cursor_range in cursor_ranges:
t = Process(target=calc_byte_count, args=(file_path, byte_value, cursor_range[0], cursor_range[1], mylock, result))
processes.append(t)
for t in processes:
t.start()
for t in processes:
t.join()
print("result:", result.value)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--num_thread", dest="num_thread", type=int, default=10, help="number of processes")
parser.add_argument("--file_path", dest="file_path", default="test1.txt", help="path of file")
parser.add_argument("--byte_var", dest="byte_var", default=b"p", help="byte value")
args = parser.parse_args()
num_thread = args.num_thread
file_path = args.file_path
byte_var = args.byte_var
start_time = time.time()
print(f"starting at {start_time}")
main(num_thread=num_thread, file_path=file_path, byte_value=byte_var)
end_time = time.time()
print(f"all done at {end_time}, cost: {(end_time-start_time)*1000}")
可以看到,多进程版本读取文件并计数的时间开销明显比单线程和多线程版本快。
线程、文件和正则表达式
问题:假设你有一个非常大的邮件文本。你的任务是使用正则表达式识别email地址和web站点的url,将识别结果保存到html文件中。使用线程对这个大文本文件的转换过程进行分割,最后整合所有结果到一个新的html文件中。
线程和网络(TODO)
实现多线程版本的聊天服务应用。
线程和web编程(TODO)
使用多线程进行网页下载
线程池
基于线程池实现生产者-消费者模型,任意数量的消费者线程,每个线程可以在任一时刻处理或消费队列中的多个对象.(在prodcons.py的基础上修改)
"""生产者消费者模型(线程池版本)
基于Queue队列实现生产者消费者模型
"""
from random import randint
from time import sleep, ctime
from queue import Queue
from threading import Thread
def writeQ(queue:Queue):
print(f"write queue starting at {ctime()}")
# put方法会阻塞直到queue有数据
queue.put(1)
print(f"write queue done at {ctime()}, currently queue size: {queue.qsize()}")
def readQ(queue: Queue):
print(f"read queue starting at {ctime()}")
if queue.empty():
print("try to read queue, but queue is empty")
else:
# get_nowait()为非阻塞调用,相当于get(block=False)
print(queue.get_nowait())
print(f"read queue done at {ctime()}, currently queue size: {queue.qsize()}")
def writer(queue, nloops):
for i in range(nloops+3):
writeQ(queue)
sleep(randint(1, 2))
def reader(queue,nloops):
for i in range(nloops):
readQ(queue)
sleep(randint(3,10))
def main():
nloops = randint(8,15)
nconsumers = 4
assert nloops >= nconsumers
print(f"initializing {nloops}")
q = Queue(10)
threads = [Thread(target=writer, args=(q, nloops), name=writer.__name__)]
for i in range(nconsumers):
threads.append(Thread(target=reader, args=(q, nloops//nconsumers), name=reader.__name__))
for t in threads:
t.start()
for t in threads:
t.join()
print(f"all done at {ctime()}")
if __name__ == "__main__":
main()
文件
创建一些线程来统计一组文本文件中包含多少行,可以选择要使用的线程的数量。
单线程实现统计一个目录下文本文件的行数
"""
单线程统计文本文件有多少行
"""
import os
import sys
import time
file_dir = str(sys.argv[1])
file_list = os.listdir(file_dir)
print(f"analysis dir: {file_dir}, total {len(file_list)} files")
result = 0
start_time = time.time()
for file in file_list:
with open(os.path.join(file_dir, file), 'r') as f:
count = 0
for line in f:
count += 1
result += count
print(file, count)
print(f"result: {result}")
end_time = time.time()
print(f"cost {(end_time-start_time)}s")

多线程统计一组文本文件的行数
"""
多线程统计文本文件有多少行
"""
import os
import sys
import time
from threading import Thread, Lock
file_dir = str(sys.argv[1])
file_list = os.listdir(file_dir)
print(f"analysis dir: {file_dir}, total {len(file_list)} files")
result = 0
lock = Lock()
def count_single_file(file_path):
global result
with open(file_path, 'r') as f:
count = 0
for _ in f:
count += 1
# with lock:
result += count
print(os.path.basename(file_path), count)
start_time = time.time()
threads = []
for file in file_list:
t = Thread(target=count_single_file, args=(os.path.join(file_dir,file),))
threads.append(t)
for t in threads:
t.start()
for t in threads:
t.join()
print(f"result: {result}")
end_time = time.time()
print(f"{(end_time-start_time)}s")

线程池统计一组文本文件行数
import os
import sys
import time
from concurrent.futures import ThreadPoolExecutor
file_dir = str(sys.argv[1])
nthreads = int(sys.argv[2])
file_list = os.listdir(file_dir)
print(f"analysis dir: {file_dir}, total {len(file_list)} files")
print(f"Use {nthreads} threads.")
result = 0
def count_single_file(file_path):
global result
with open(file_path, 'r') as f:
count = 0
for _ in f:
count += 1
with lock:
result += count
print(os.path.basename(file_path), count)
return count
start_time = time.time()
futures = []
with ThreadPoolExecutor(max_workers=nthreads) as executor:
for file in file_list:
futures.append(executor.submit(count_single_file, os.path.join(file_dir, file)))
# for future in futures:
# print(future.result())
print(f"result: {result}")
end_time = time.time()
print(f"{(end_time-start_time)}s")
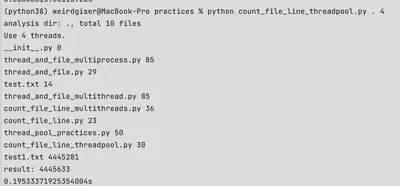
同步原语
研究threading模块中的每个同步原语。描述他们做了什么,在什么情况下有用,然后为每个同步原语创建可运行的代码示例。
threading库中的同步原语包括:锁、信号量、条件变量、事件、计时器、障碍。
锁(Lock)
锁是基本的同步原语,可以限制某一共享资源在同一时刻只能被一个线程访问到(串行执行该部分代码)。threading中有Lock、RLock两个对象,Lock对象由底层线程库_thread的_allocate_lock方法返回。
Lock示例
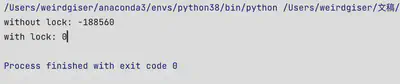
多个线程同时修改一个共享变量,如果线程访问共享变量时未加锁或者其他数据同步措施,可能会导致多线程结果不符合预期。注意:未使用锁不一定会出问题,但有可能出问题;如下面的代码示例:同时开启两个线程,修改一个全局变量,每个线程均须执行一百万次对应的函数,其中一个线程执行的函数是对共享变量result增加1,另一个线程执行的函数时对共享变量result的值减1. 我们期望两个线程执行完后得到的result为0,但如果线程修改全局变量时未加锁,实际上我们很难得到正确的结果。但是如果每个线程修改共享变量前先获取锁对象,修改完成后再释放锁,就可以稳定得到正确结果。
from threading import Lock, Thread
lock = Lock()
COUNT = 1000000
result = 0
def func_incr_with_lock_demo():
global result
for _ in range(COUNT):
with lock:
result += 1
def func_decr_with_lock_demo():
global result
for _ in range(COUNT):
with lock:
result -= 1
def func_incr_without_lock_demo():
global result
for _ in range(COUNT):
result += 1
def func_decr_without_lock_demo():
global result
for _ in range(COUNT):
result -= 1
if __name__ == "__main__":
threads = []
# num_threads = 4
threads.append(Thread(target=func_incr_without_lock_demo))
threads.append(Thread(target=func_decr_without_lock_demo))
for t in threads:
t.start()
for t in threads:
t.join()
print("without lock:", result)
result = 0
threads = []
# num_threads = 4
threads.append(Thread(target=func_incr_with_lock_demo))
threads.append(Thread(target=func_decr_with_lock_demo))
for t in threads:
t.start()
for t in threads:
t.join()
print("with lock:",result)
assert result == 0
RLock
尽管有时候使用Lock能保证多线程程序结果的正确性,但是一些特定的场景下Lock并不使用:比如在一个线程中递归地获取同一个锁,类似如下函数所做的一样:如果lock_obj是threading.Lock对象,那么当递归函数未达到递归终止条件时,第一次执行函数所获取的锁对象将得不到释放,导致递归层数增加时该线程无法再次获得同一个锁对象,从而导致死锁。
def recurve_call_lock(remaining: int, lock_obj):
lock_obj.acquire()
if remaining == 0:
return 0
else:
try:
print(f"Current {threading.current_thread().getName()}")
return recurve_call_lock(remaining-1, lock_obj)
finally:
lock_obj.release()
以上情况,可以使用可重入锁对象RLock解决。RLock允许同一个线程多次获得同一把锁,每获得一次锁,锁对象中的计数变量会增加,每释放一次锁,计数变量会减1,只有当锁变量的计数值变为0其他线程才有机会获得这个锁。所以,当同一个线程需要多次获取同一个锁对象的时候(如递归场景),使用可重入锁RLock会比Lock对象更合适,因为RLock可以跟踪锁对象的所有权(当前被哪个线程获取)和递归级别(被获取的次数)。

下面的代码示例演示了RLock在同一个线程的同一个函数递归调用场景可正常工作,而Lock则会导致线程阻赛(因为死锁)的情况:
"""RLock Demo"""
import threading
from threading import Lock, RLock
rlock = RLock()
lock = Lock()
def recurve_call_lock(remaining: int, lock_obj):
lock_obj.acquire()
if remaining ==0:
return 0
else:
try:
print(f"Current {threading.current_thread().getName()}")
return recurve_call_lock(remaining-1, lock_obj)
finally:
lock_obj.release()
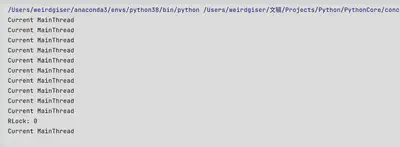
if __name__ == "__main__":
result = recurve_call_lock(10, rlock)
print(f"RLock: {result}")
result = recurve_call_lock(10, lock)
print("Lock:", result)
条件变量(Condition)
如果我们需要让多个线程之间基于复杂的条件决定运作与否,可以考虑使用条件变量(Condition)
wait()方法允许线程等待某个条件成立
notify()允许线程在某个条件成立时通知(notify)其他线程,也可使用notify_all()方法通知其他所有线程
条件变量跟互斥锁通常一起使用,Condition对象的wait和notify方法的实现里分别包括互斥锁的获取和释放,实际上当我们创建Condition实例时,可以指定一个锁对象初始化Condition对象,默认会使用RLock来进行初始化。
# threading.py
class Condition:
"""Class that implements a condition variable.
A condition variable allows one or more threads to wait until they are
notified by another thread.
If the lock argument is given and not None, it must be a Lock or RLock
object, and it is used as the underlying lock. Otherwise, a new RLock object
is created and used as the underlying lock.
"""
def __init__(self, lock=None):
if lock is None:
lock = RLock()
self._lock = lock
# Export the lock's acquire() and release() methods
self.acquire = lock.acquire
self.release = lock.release
# If the lock defines _release_save() and/or _acquire_restore(),
# these override the default implementations (which just call
# release() and acquire() on the lock). Ditto for _is_owned().
try:
self._release_save = lock._release_save
except AttributeError:
pass
try:
self._acquire_restore = lock._acquire_restore
except AttributeError:
pass
try:
self._is_owned = lock._is_owned
except AttributeError:
pass
self._waiters = _deque()
.......
以下代码演示条件变量的作用:生产者-消费者简单模型,当商品数量为0时,消费者线程进行等待,直到生产者线程生产出商品并发送通知;当商品数量满时,生产者线程进行等待,直到消费者对商品进行消费并对生产者线程发起通知为止。
"""
条件变量示例:生产者消费者模型,当产品已满,生产者会通知消费者进行消费,当产品为空,消费者会通知生产者进行生产
"""
import time
from threading import Condition, Thread
# 初始化一个条件变量对象
cond = Condition()
# 初始化上品质
MIN_PRODUCT = 0
MAX_PRODUCT = 8
num_products = 5
def consumer():
global num_products
while True:
with cond:
if num_products == MIN_PRODUCT :
print(f"Empty products, {num_products}")
cond.wait()
else:
print(f"consumer products, {num_products}")
time.sleep(0.12)
num_products -= 1
cond.notify()
def producer():
global num_products
while True:
with cond:
if num_products == MAX_PRODUCT:
print(f"Full of products, {num_products}")
# 当产品已满时,生产者线程进行等待,直到消费者消费后才继续生产
cond.wait()
else:
print(f"producer products, {num_products}")
time.sleep(0.15)
num_products += 1
cond.notify()
if __name__ == "__main__":
t1 = Thread(target=producer)
t2 = Thread(target=consumer)
threads = [t1, t2]
for t in threads:
t.start()
for t in threads:
t.join()

信号量(Semaphore)
有时候我们希望用多个线程对同一个或者同一组资源进行并发访问,但希望控制并发线程的数量或者控制并发线程的执行顺序,可以考虑使用信号量(Semaphore)。threading库提供了两种信号量对象:Semaphore和BoundedSemaphore,其中后者相比于前者多了一些特性:释放次数不允许超过信号量初始值(释放操作会使得信号量增加,BoundedSemaphore限制信号量的计数值不能超过初始值),具体用法见candy.py
# threading,py
class Semaphore:
"""This class implements semaphore objects.
Semaphores manage a counter representing the number of release() calls minus
the number of acquire() calls, plus an initial value. The acquire() method
blocks if necessary until it can return without making the counter
negative. If not given, value defaults to 1.
"""
# After Tim Peters' semaphore class, but not quite the same (no maximum)
def __init__(self, value=1):
if value < 0:
raise ValueError("semaphore initial value must be >= 0")
self._cond = Condition(Lock())
self._value = value
def acquire(self, blocking=True, timeout=None):
"""Acquire a semaphore, decrementing the internal counter by one.
When invoked without arguments: if the internal counter is larger than
zero on entry, decrement it by one and return immediately. If it is zero
on entry, block, waiting until some other thread has called release() to
make it larger than zero. This is done with proper interlocking so that
if multiple acquire() calls are blocked, release() will wake exactly one
of them up. The implementation may pick one at random, so the order in
which blocked threads are awakened should not be relied on. There is no
return value in this case.
When invoked with blocking set to true, do the same thing as when called
without arguments, and return true.
When invoked with blocking set to false, do not block. If a call without
an argument would block, return false immediately; otherwise, do the
same thing as when called without arguments, and return true.
When invoked with a timeout other than None, it will block for at
most timeout seconds. If acquire does not complete successfully in
that interval, return false. Return true otherwise.
"""
if not blocking and timeout is not None:
raise ValueError("can't specify timeout for non-blocking acquire")
rc = False
endtime = None
with self._cond:
while self._value == 0:
if not blocking:
break
if timeout is not None:
if endtime is None:
endtime = _time() + timeout
else:
timeout = endtime - _time()
if timeout <= 0:
break
self._cond.wait(timeout)
else:
self._value -= 1
rc = True
return rc
__enter__ = acquire
def release(self):
"""Release a semaphore, incrementing the internal counter by one.
When the counter is zero on entry and another thread is waiting for it
to become larger than zero again, wake up that thread.
"""
with self._cond:
self._value += 1
self._cond.notify()
def __exit__(self, t, v, tb):
self.release()
import random
import threading
import time
from threading import Thread, Semaphore, BoundedSemaphore
NUM_THREADS = 10
sema = Semaphore(value=5)
def visit_resource(thread_name):
"""
注意:由于print方法不是线程安全的,所以多线程执行print函数时,控制台的输出可能会出现一些混乱
:param thread_name:
:return:
"""
print(f"current thread: {thread_name} is waiting")
sema.acquire()
print(f"current thread: {thread_name}, thread count: {threading.active_count()}")
# time.sleep(random.randint(1,3))
sema.release()
print(f"current thread: {thread_name} is released")
if __name__ == "__main__":
threads = [Thread(target=visit_resource, args=(i,)) for i in range(NUM_THREADS)]
for t in threads:
t.start()
for t in threads:
t.join()

注:当信号量的初始计数为1时,信号量可称为二元信号量,此时信号量作用相当于互斥锁,当然为了代码轻量化考虑,当你需要互斥锁时,直接使用Lock或RLock会更加理想。
信号量本质上可以理解为一个整型的计数器。
事件(Event)
(TODO)
计时器(Timer)
(TODO)
障碍(Barrier)
(TODO)
threading模块debug
(TODO)
小结
进程是正在运行的程序实例,拥有独立的内存空间,是操作系统资源分配的最小单位。
线程是进程内的执行单元,一个进程内至少有一个线程,多个线程间共享该进程内的大部份资源(内存、文件描述符、全局变量/静态变量、环境变量)。线程由操作系统调度。
进程、线程、协程三个层级逐级往下,上下文切换的开销逐级降低。
python多线程适合IO密集型任务的性能提高,计算密集型任务效果极其有限
由于Python GIL特性,处理同样的任务,多线程的程序未必比单线程效率高,但由于GIL会在IO阻塞时被释放,所以对于IO密集型任务多线程有可能提高性能。比如本人在公司开发测试一个并行数据迁移(大文件复制)功能时,10个线程并发数据迁移耗时8min(单线程数据迁移约1min一个文件),4个线程并发迁移耗时60~70s,迁移效率明显提高。
- 协程又被称为轻量级线程,极其适合IO密集型任务,如web服务的高并发场景。一个线程内可以并发运行多个协程,当某个协程被阻塞时,可以暂停该协程并切换到其他就绪状态的协程执行任务。
参考文档
queue — 一个同步的队列类 — Python 3.11.4 文档
threading — Thread-based parallelism — Python 3.11.4 documentation
cpython/Python/ceval_gil.c at main · python/cpython · GitHub