Neo4j基本使用与Cypher语言基础
图数据库简介
什么是图?
图是由实体以及实体间的关系组成的结构,这种结构可以抽象表示现实世界中的事物及事物间的关系。我们可以用节点/Node/Vertex表示实体、用节点间的连边/Ralationship/Edge/表示节点间的关系。
举例来说,我们的朋友圈可以通过图结构进行抽象,每个人作为一个节点,若两个人之间存在关系则认为两个节点具有连边,由此构造出社交网络。
更多关于图的介绍或相关研究可以查阅图论、复杂网络科学,前者为侧重抽象数学层面的领域,后者更侧重对使用图结构对复杂系统的性质进行建模分析。
为什么需要图数据库?
众所周知,关系型数据库也可以存储“图‘结构的数据,我们可以通过设计一张MySQL表存储某一个实体(节点)的信息,每个实体所具有的属性对应着MySQL表的字段(列)。通过关联表或者外键关联关系等方式存储节点间的关系,这样的设计可以支持对图数据的存储和检索。那么,为什么需要在一般的关系型数据库之外,专门设计一种叫“图数据库”的东西呢?
这里提一句奥卡姆剃刀原则:“如无必要,勿增实体。“
那么,图数据库的必要性是?
主流关系型数据库的缺陷
所谓缺陷,其实不是绝对的缺陷,而是特定需求、场景下的缺陷。假设我们要对复杂网络相关的数据进行分析,其中可能会经常需要对节点的特征进行深度优先的搜索。在一般关系型数据库中,我们查询具有一阶关联关系的节点对信息需要使用JOIN关联两个表(一个节点吧,一个节点关系表)进行查询,如果涉及到多阶关系的查询(如查询节点的多阶邻居,甚至更复杂的多种关系),那么关系型数据库就需要同时JOIN多个表乃至使用子查询,而针对我们的关系查询需求而言,关系数据库的查询会变得非常复杂且效率不高。
假设你已经认同了关系数据库在涉及高阶关系查询上的困境,再进一步考虑一个场景:我们可能会需要经常对关系数据(包括关系的属性)进行更新!比如金融、商业领域的数据变化频率很高,关系型数据库既然在处理高阶关系查询时效率就低,那数据更新就更加不用期待了。
因此,我们需要一种专用的数据库,用于存储和处理图数据并能够在处理复杂关系查询/更新时有较高的效率,这就是图数据库,其中最具有代表性的一种实现就是Neo4j。

权衡(Trade Off)
当然,使用图数据库能够进行高效率复杂关系查询,但是在存储空间和内存需求上要求更高了。所以,如果你对数据库的需求不在于显式存储数据关系,那可以使用关系型数据库节省内存空间。
Neo4J生态工具
Neo4J Desktop: Neo4j的桌面端管理软件。
Neo4J Browser:Neo4J的在线浏览器接口,可以查询管理数据库中的数据,提供使用Cypher语言对图数据进行基本可视化的功能。也提供了很多快捷命令(如用户添加、角色添加等)
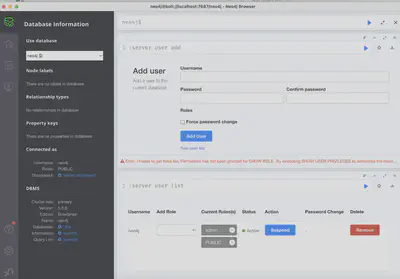
Cypher语言
基本介绍
类似SQL在MySQL、PostgreSQL等数据库中的作用,Cypher就是图数据库的一种查询语言。但Cypher的使用与SQL却有很多不同。总结起来,Cypher查询语句的特征可以总结为“模式”查询,即通过描述实体-关系的“模式”,并为模式各组成部分进行变量命名,将需要的变量返回即可得到查询结果,或者修改、删除对应变量即可完成对指定条件的数据进行变更。
Cypher CheetSheet:Cypher Cheat Sheet - Neo4j Documentation Cheat Sheet
Cypher文档:Introduction - Cypher Manual
一些工具:cypher-shell、neo4j-admin
关于Cypher的系统性学习可以注册Neo4j官网中的课程,完成后可以获得证书:

下面仅为个人笔记,便于查阅:
基本关键字
Cypher是对节点、节点间的关系及属性进行增删改查的类SQL语言。主要有如下关键字:
MATCH
MERGE
CREATE
SET
DELETE
DETACH DELETE
RETURN
查询节点
查询某种关系类型的根节点
MATCH (n:NodeType)
WHERE NOT EXISTS(()<-[:RelationType]-(n:NodeType))
RETURN n
查询关系
聚合查询
Cypher语言中的聚合函数与SQL中的命名类似,计算总数的函数为COUNT,计算总和的函数为SUM。
聚合函数及使用示例
COUNT
SUM
查询数据库中存在的节点和关系总数
MATCH ()-[r]->() RETURN count(r)
MATCH (n) RETURN count(n)
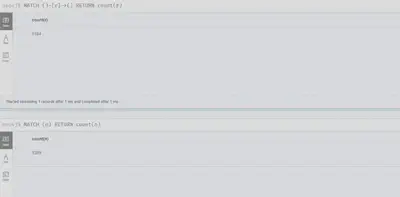
查询各类节点的数量
MATCH (n) RETURN labels(n), count(*)
查看各类关系的数量
MATCH ()-[r]->()
RETURN type(r), count(*)
模糊查询
模糊查询并非使用LIKE关键字,而是使用CONTAINS,如:
MATCH p=(n:NodeType)-->() WHERE n.name CONTAINS '需要模糊查询的关键字' RETURN p
批量变更关系类型
MATCH (a)-[r:OLD_RELATION]->(b)
CREATE (a)-[rNew:NEW_RELATION]->(b)
SET rNew = r
WITH r
DELETE r
删除数据
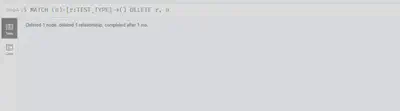
删除关系
MATCH (n)-[r:TEST_TYPE]->()
DELETE r, n
删除孤立节点
MATCH (n:NodeType) WHERE NOT (n)--() DELETE n
多跳查询
二跳查询
MATCH p=(n:NodeType{name:'NodeName'})-[r:Rel1]->()-[:Rel2]->(re) RETURN re.name,re.id
递归多跳查询
在关系类型后加*符号即可实现递归查询
MATCH p=(n:NodeType{name:'NodeName'})-[r:Rel1*]->(re) RETURN re.name,re.id
Neo4j查询结果集导出csv/json
通过Cypher命令查出的表格数据可以使用Neo4j Browser的Export CSV/Export JSON功能导出。
图数据库示例数据集
图数据库图算法支持
Python操作Neo4j数据库
py2neo github 1.2 star
neo4j github 800+ star
Nginx代理转发Neo4j服务
有时候可能希望将neo4j默认服务(neo4j browser等)开放给互联网上的用户使用,并且希望希望通过nginx进行反向代理,简单的做法可以参考如下流程:
- 配置nginx.conf文件,新建stream代理规则,用于支持neo4j采用websocket协议通信的服务.
stream {
upstream neo4j {
server 127.0.0.1:7687;
}
server {
listen YOUR_PORT;
proxy_pass neo4j;
}
}
- 配置xxx.conf文件,新建http server代理规则,用于支持neo4j browser(http服务).
server {
listen YOUR_PORT;
server_name YOUR_HOSTNAME_OR_IP;
location /graph/ {
proxy_hide_header Content-Security-Policy;
proxy_hide_header X-Frame-Options;
proxy_pass http://127.0.0.1:7474/;
}
}
http://127.0.0.1:7474/是neo4j Browser的默认服务地址,当然也可以在配置文件修改默认端口。
这两条配置是为了让neo4j browser可以通过iframe嵌入到另一个站点,否则进行iframe嵌入会受到限制。
proxy_hide_header Content-Security-Policy;
proxy_hide_header X-Frame-Options;