基于Grafana+Prometheus的监控预警技术
现代 IT 系统架构日益复杂,监控已成为可靠性与稳定性的基石。本文站在Google SRE 以及 Prometheus、Grafana 等业界最佳实践的肩膀上, 梳理一套监控预警方案。
在运维和开发中,我们常常被以下痛点困扰:
- 系统"看不见":故障发生时,不知道哪个环节出问题;
- 定位"找针":日志和指标分散在不同工具,排查效率低下;
- 告警"泛滥":简单阈值告警刷屏,真正紧急的被淹没;
- 部署"磨洋工":多种监控组件各自配置,重复劳动且易出错。
要打通这些痛点,监控方案必须具备:
- 全链路可观察:覆盖宿主机、容器和业务层指标;
- 精准告警:基于标签路由与抑制(Inhibition),杜绝噪声;
- 灵活可视化:支持多维度分析和模板快速复用;
- 一键部署与扩展:参数化配置,支持水平扩容。
参考 CNCF 云原生监控图谱、Google SRE 等行业实践,我们选用了以下开源技术栈:
Prometheus:Pull 模式抓取,TSDB 存储,PromQL 强大查询。
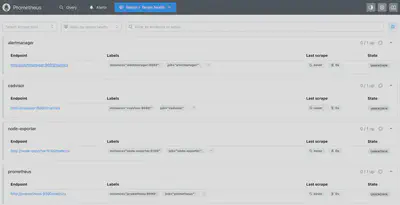
Node Exporter & cAdvisor:零改动采集宿主机与容器资源指标。
业务
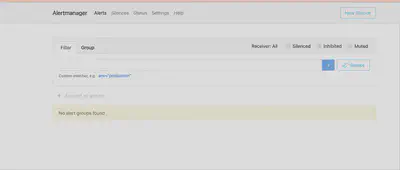
/metrics:集成 Prometheus SDK,暴露自定义业务指标。Alertmanager:标签路由、分组与抑制,多渠道精准告警。
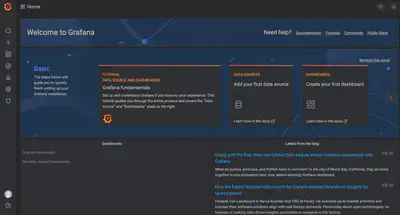
Grafana:可视化门户,支持 PromQL、模板化 Dashboard。
可选 Nginx 四层代理:统一入口、TLS 终端与限流控制。
通过这套方案,我们能在 15s 内发现故障,借助 PromQL 精准定位,并将告警自动推送给负责人,实现高效运维。
参考资料
- Google SRE Book: https://sre.google/books/
- Prometheus 官方文档: https://prometheus.io/docs/introduction/overview/
- Grafana 官方文档: https://grafana.com/docs/
- Alertmanager 文档: https://prometheus.io/docs/alerting/alertmanager/