Langchain——LLM编程新范式
目录
前言
LangChain是一个封装了AI应用常用工具的库,将大模型常见应用进行了模块化和工具化,使开发者可以便利地使用各厂商发布的大模型或自己训练的大模型完成下游任务(如Text2SQL)。
模块化设计
提供多种预制模块、组件,如提示模板、LLM、输出解析、智能体、记忆、工具集。
链式调用(提示模板、语言模型、数据结构)
将多个模块或功能组件串联形成工作流,以完成复杂任务。
扩展性
支持多种流行的AI模型和算法,同时允许添加新的模型
RAG
核心思想:让大模型通过理解和推理来决定执行什么操作以及执行的顺序,最终完成预定任务。
核心模块
数据集加载和解析
数据集加载
导入使用:
from langchain_community.document_loaders import PyPDFLoader
from langchain_community.document_loaders import Docx2txtLoader
from langchain_community.document_loaders import TextLoader
from langchain_community.document_loaders import PDFPlumberLoader
......
- 演示解析JSON文件构造文档集合
Json数据组织如下:希望读取其中的列表,对content字段内容进行切片并向量化,title、url等字段作为元数据。
{"data":
[{"title":"", "content":"", "url": ""},
{"title":"", "content":"", "url": ""},
{"title":"", "content":"", "url": ""}]
}
import os
from langchain_community.document_loaders import TextLoader, JSONLoader
def metadata_func(record: dict, metadata: dict) -> dict:
# 提取元数据
metadata["title"] = record.get("title")
metadata["release_time"] = record.get("release_time")
metadata["source"] = record.get("source")
metadata["url"] = record.get("url")
return metadata
def get_documents(data_dir):
"""
Loads all documents from the data directory
"""
documents = []
for file in os.listdir(data_dir):
# 构建完整的文件路径
file_path = os.path.join(data_dir, file)
if file.endswith('.json'):
# 通过content_key指定以.data[]下对象的content字段作为文档内容
loader = JSONLoader(file_path, jq_schema='.data[]', content_key="content", metadata_func=metadata_func)
documents.extend(loader.load())
else:
raise NotImplementedError("not supported")
return documents

LangChain提供了多种数据集切割的类库,如下所示为RecursiveCharacterTextSplitter的部分源码
class TextSplitter(BaseDocumentTransformer, ABC):
"""Interface for splitting text into chunks."""
def __init__(
self,
chunk_size: int = 4000,
chunk_overlap: int = 200,
length_function: Callable[[str], int] = len,
keep_separator: Union[bool, Literal["start", "end"]] = False,
add_start_index: bool = False,
strip_whitespace: bool = True,
) -> None:
# ......
class RecursiveCharacterTextSplitter(TextSplitter):
"""Splitting text by recursively look at characters.
Recursively tries to split by different characters to find one
that works.
"""
def __init__(
self,
separators: Optional[List[str]] = None,
keep_separator: Union[bool, Literal["start", "end"]] = True,
is_separator_regex: bool = False,
**kwargs: Any,
) -> None:
"""Create a new TextSplitter."""
super().__init__(keep_separator=keep_separator, **kwargs)
self._separators = separators or ["\n\n", "\n", " ", ""]
self._is_separator_regex = is_separator_regex
def _split_text(self, text: str, separators: List[str]) -> List[str]:
"""Split incoming text and return chunks."""
final_chunks = []
# Get appropriate separator to use
separator = separators[-1]
new_separators = []
for i, _s in enumerate(separators):
_separator = _s if self._is_separator_regex else re.escape(_s)
if _s == "":
separator = _s
break
if re.search(_separator, text):
separator = _s
new_separators = separators[i + 1 :]
break
_separator = separator if self._is_separator_regex else re.escape(separator)
splits = _split_text_with_regex(text, _separator, self._keep_separator)
# Now go merging things, recursively splitting longer texts.
_good_splits = []
_separator = "" if self._keep_separator else separator
for s in splits:
if self._length_function(s) < self._chunk_size:
_good_splits.append(s)
else:
if _good_splits:
merged_text = self._merge_splits(_good_splits, _separator)
final_chunks.extend(merged_text)
_good_splits = []
if not new_separators:
final_chunks.append(s)
else:
other_info = self._split_text(s, new_separators)
final_chunks.extend(other_info)
if _good_splits:
merged_text = self._merge_splits(_good_splits, _separator)
final_chunks.extend(merged_text)
return final_chunks
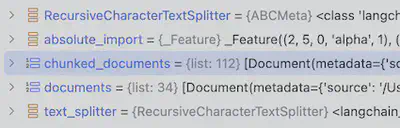
简单使用方式, 将文档集切分成200词左右的文档切片,切片间重叠Token为10个以内:
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=200, chunk_overlap=10)
chunked_documents = text_splitter.split_documents(documents)
输出解析器
字符串输出
结构化输出(Json、Yaml等)
示例:Json输出(朴素版)
class StructuredBulletAgentTestCase(unittest.TestCase):
def setUp(self):
self.agent = StructuredBulletSummaryAgent(TongyiLLM.from_model_config(model_type=QwenChatModelTypeEnum.QWEN_TURBO_0919))
print("Model_config", self.agent.llm.model_config)
print("Model_name", self.agent.llm.model_name)
def test_run(self):
resp = self.agent.run(topic="小米",
section="电饭煲",
topic_description="小米产品的市场布局与优势调研",
section_description="电饭煲相比竞品的优势和劣势",
formatted_text="")
self.assertIsNone(resp.err)
self.assertIsNotNone(resp.content)
print(resp)
self.assertIsInstance(resp.content, list)
print(len(resp.content))
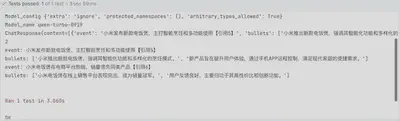
for event in resp.content:
print(f"event: {event.get('event')}\nbullets: {event.get('bullets')}")
示例:Json输出(借助JsonOutputParser)
langchain_core.output_parsers.json.JsonOutputParser — 🦜🔗 LangChain 0.2.17
Prompt示例
# 输出格式与字段说明
1. 输出JSON Array格式
2. 字段说明:
- event:事件描述
- citation_token:引用新闻的编号
- event_details:事件要点,包括具体行动或决策、数据或指标等。
# 输出格式示例(仅作格式参考)
[{{ "event": "事件描述1", "citation_token": "【新闻1】", "event_details": [ "事件要点1,包括具体行动或决策。", "事件要点2,包含具体数据或指标。" ]}}, {{ "event": "事件描述2", "citation_token": "【新闻2】", "event_details": [ "事件要点1,包括具体行动或决策。", "事件要点2,包含具体数据或指标。" ]}}, {{ "event": "事件描述3", "citation_token": "【新闻3】【新闻4】", "event_details": [ "事件要点1,包括具体行动或决策。", "事件要点2,包含具体数据或指标。" }} ]
# 注意事项
- 不要直接输出示例。示例中的事件1和事件2仅为占位符,输出结果应以实际事件替代。
- 审慎选择,确保信息准确无误,特别是数据和指标的准确性。
- 直接提供新闻筛选结果,无需解释为何提供该结果。
代码示例:
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.prompts import PipelinePromptTemplate, PromptTemplate
@dataclass
class EventItem:
event: str
citation_token: str
event_details: List[str]
@classmethod
def from_dict(cls, event_dict):
return cls(**event_dict)
class JsonBulletAssistant:
def __init__(self, llm = None):
self.system_prompt = MyPromptTemplate.from_file(BULLET_JSON_PROMPT_FILE)
input_prompt = PromptTemplate.from_template("{collected_info}")
final_prompt = PromptTemplate.from_template("""
{system_prompt}
{input_prompt}
""")
self.pipeline_prompt = PipelinePromptTemplate(final_prompt=final_prompt,
pipeline_prompts=[("system_prompt", self.system_prompt),
("input_prompt", input_prompt)])
output_parser = JsonOutputParser()
self.llm = llm
self.chain = self.pipeline_prompt | self.llm | output_parser
测试代码片段:
class TestJsonBulletAssistant(unittest.TestCase):
def setUp(self):
llm = TongyiLLM.from_model_type(ModelTypeEnum.QWEN_TURBO_1101.value)
print(llm.model_name, llm.dashscope_api_key)
self.bullet_assistant = JsonBulletAssistant(llm=llm)
def test_get_structure(self):
result = self.bullet_assistant.invoke(topic="华为u", section="asdfasdf",
topic_description="topic_description",
section_description="section_description", parent_title="parent_title",
news_text="【新闻2】华为遥遥领先,预计2025年出货量将达到1000万台。\n【新闻1】华为发布了全新的手机型号,售价为1000元。")
self.assertIsNone(result.err)
self.assertIsNotNone(result.content)
print(result.content)
self.assertIsInstance(result.content, list)
for event in result.content:
event_obj = EventItem(**event)
print(event_obj)
测试结果输出:
# Output
[{'event': '华为发布全新手机型号', 'citation_token': '【新闻1】', 'event_details': ['发布了售价为1000元的新手机型号。']}, {'event': '华为2025年出货量预测', 'citation_token': '【新闻2】', 'event_details': ['预计2025年出货量将达到1000万台。']}]
EventItem(event='华为发布全新手机型号', citation_token='【新闻1】', event_details=['发布了售价为1000元的新手机型号。'])
EventItem(event='华为2025年出货量预测', citation_token='【新闻2】', event_details=['预计2025年出货量将达到1000万台。'])

示例: Pydantic模型输出
https://github.com/Coolgiserz/data-interpret-experiments
提示词模板
PromptTemplate是提示模板对象,其中from_template方法允许直接从字符串模板创建PromptTemplate对象。
链式调用
from langchain.schema.output_parser import StrOutputParser
PROMPT_TEMPLATE_DIR = Path(__file__).parent / "templates"
BULLET_PROMPT_FILE = PROMPT_TEMPLATE_DIR / "bullet.ptext"
class MyAssistant:
def __init__(self, llm = None):
self.system_prompt = MyPromptTemplate.from_file(BULLET_PROMPT_FILE)
output_parser = StrOutputParser()
self.llm = llm
self.chain = self.system_prompt | self.llm | output_parser
def invoke(self, topic, section, parent_title="", section_description="", topic_description=""):
return self.chain.invoke(input=dict(topic=topic,
section=section,
parent_title=parent_title,
section_description=section_description,
topic_description=topic_description))
系统提示词模板和用户提示词模板组合
from forag.prompts import SystemMessagePromptTemplate, HumanMessagePromptTemplate, ChatPromptTemplate
PROMPT_TEMPLATE_DIR = Path(__file__).parent / "prompt_templates"
encoding = "utf-8"
class BulletSummaryAgent(Agent):
def __init__(self, llm: BaseLLM):
self.llm = llm
prompt_file = os.path.join(PROMPT_TEMPLATE_DIR, "bullet_unstructured.plain")
with open(prompt_file, "r", encoding=encoding) as f:
self.system_prompt = SystemMessagePromptTemplate.from_template(f.read())
self.human_prompt = HumanMessagePromptTemplate.from_template("{formatted_text}")
prompt_template = ChatPromptTemplate.from_messages([self.system_prompt, self.human_prompt])
assert self.llm is not None, "llm must be set."
self.chain = prompt_template | self.llm
def run(self, topic: str, section: str, formatted_text, topic_description: str="",
section_description="") -> ChatResponse:
if len(topic.strip()) == 0:
raise ParameterError("topic must not be None.")
content = None
err = None
try:
content = self.chain.invoke(input=dict(topic=topic,
section=section,
topic_description=topic_description.strip(),
section_description=section_description.strip(),
formatted_text=formatted_text
))
except Exception as e:
logger.error(f"{self.__class__} run error with parameter ({topic}, {section}, {formatted_text}): {repr(e)}")
logger.error(traceback.format_exc())
err = e
return ChatResponse(content=content, err=err)
Fewshot提示词模版
常见问题
- 保存模板时中文提示词模板乱码(序列化成unicode)
template = PromptTemplate.from_template(prompt_text)
print(template)
template.save("prompt/prompt.yaml")
问题原因:BasePromptTemplate保存提示词时,未考虑中文字符,默认序列化后结果都使用ascii表示。
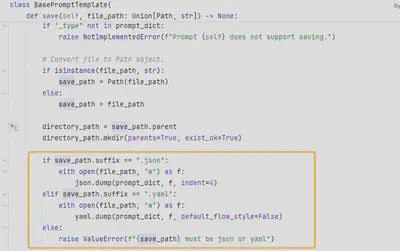
解决思路:
自行通过json、yaml序列化,如使用json.dumps时指定参数ensure_ascii=False确保非Asicii字符原样输出。
实现PromptTemplate的子类,重写save方法,确保汉字字符被正确处理

少样本提示模板
FewShotPromptTemplate,通过示例教模型如何回答。
工具调用
目前内置工具:
# langchain_community/agent_toolkits/load_tools.py
_EXTRA_LLM_TOOLS: Dict[
str,
Tuple[Callable[[Arg(BaseLanguageModel, "llm"), KwArg(Any)], BaseTool], List[str]],
] = {
"news-api": (_get_news_api, ["news_api_key"]),
"tmdb-api": (_get_tmdb_api, ["tmdb_bearer_token"]),
"podcast-api": (_get_podcast_api, ["listen_api_key"]),
"memorize": (_get_memorize, []),
}
_EXTRA_OPTIONAL_TOOLS: Dict[str, Tuple[Callable[[KwArg(Any)], BaseTool], List[str]]] = {
"wolfram-alpha": (_get_wolfram_alpha, ["wolfram_alpha_appid"]),
"google-search": (_get_google_search, ["google_api_key", "google_cse_id"]),
"google-search-results-json": (
_get_google_search_results_json,
["google_api_key", "google_cse_id", "num_results"],
),
"searx-search-results-json": (
_get_searx_search_results_json,
["searx_host", "engines", "num_results", "aiosession"],
),
"bing-search": (_get_bing_search, ["bing_subscription_key", "bing_search_url"]),
"metaphor-search": (_get_metaphor_search, ["metaphor_api_key"]),
"ddg-search": (_get_ddg_search, []),
"google-books": (_get_google_books, ["google_books_api_key"]),
"google-lens": (_get_google_lens, ["serp_api_key"]),
"google-serper": (_get_google_serper, ["serper_api_key", "aiosession"]),
"google-scholar": (
_get_google_scholar,
["top_k_results", "hl", "lr", "serp_api_key"],
),
"google-finance": (
_get_google_finance,
["serp_api_key"],
),
"google-trends": (
_get_google_trends,
["serp_api_key"],
),
"google-jobs": (
_get_google_jobs,
["serp_api_key"],
),
"google-serper-results-json": (
_get_google_serper_results_json,
["serper_api_key", "aiosession"],
),
"searchapi": (_get_searchapi, ["searchapi_api_key", "aiosession"]),
"searchapi-results-json": (
_get_searchapi_results_json,
["searchapi_api_key", "aiosession"],
),
"serpapi": (_get_serpapi, ["serpapi_api_key", "aiosession"]),
"dalle-image-generator": (_get_dalle_image_generator, ["openai_api_key"]),
"twilio": (_get_twilio, ["account_sid", "auth_token", "from_number"]),
"searx-search": (_get_searx_search, ["searx_host", "engines", "aiosession"]),
"merriam-webster": (_get_merriam_webster, ["merriam_webster_api_key"]),
"wikipedia": (_get_wikipedia, ["top_k_results", "lang"]),
"arxiv": (
_get_arxiv,
["top_k_results", "load_max_docs", "load_all_available_meta"],
),
"golden-query": (_get_golden_query, ["golden_api_key"]),
"pubmed": (_get_pubmed, ["top_k_results"]),
"human": (_get_human_tool, ["prompt_func", "input_func"]),
"awslambda": (
_get_lambda_api,
["awslambda_tool_name", "awslambda_tool_description", "function_name"],
),
"stackexchange": (_get_stackexchange, []),
"sceneXplain": (_get_scenexplain, []),
"graphql": (
_get_graphql_tool,
["graphql_endpoint", "custom_headers", "fetch_schema_from_transport"],
),
"openweathermap-api": (_get_openweathermap, ["openweathermap_api_key"]),
"dataforseo-api-search": (
_get_dataforseo_api_search,
["api_login", "api_password", "aiosession"],
),
"dataforseo-api-search-json": (
_get_dataforseo_api_search_json,
["api_login", "api_password", "aiosession"],
),
"eleven_labs_text2speech": (_get_eleven_labs_text2speech, ["eleven_api_key"]),
"google_cloud_texttospeech": (_get_google_cloud_texttospeech, []),
"read_file": (_get_file_management_tool, []),
"reddit_search": (
_get_reddit_search,
["reddit_client_id", "reddit_client_secret", "reddit_user_agent"],
),
}
示例:
pip install -U duckduckgo-search
pip install arxiv
from langchain.agents import load_tools, AgentType, initialize_agent
from forag.lm import TongyiLLM, QwenChatModelTypeEnum
llm = TongyiLLM.from_model_config(QwenChatModelTypeEnum.QWEN_TURBO_0919)
tools = load_tools( ["ddg-search"],)
# 初始化链
question = "介绍一下艾尔登法环"
agent_chain = initialize_agent( tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True,)
r = agent_chain.run(question)
print(r)
tools_nothing = load_tools( ["arxiv"],)
agent_chain_no_tool = initialize_agent( tools_nothing, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True,)
r = agent_chain_no_tool.run(question)
print(r)

“链“
LangChain中的“Chain”是组合和编排不同的组件从而创建复杂程序的关键。复杂的任务分解成细粒度的任务组件,将多个任务组件串联起来即为“链”。技术层面,链的核心处理逻辑是接受用户输入,使用 PromptTemplate 对其进行格式化,然后将格式化的响应传递给 LLM。
实现了链的具体功能之后,可以通过将多个链组合串联,或者将链与其他组件组合来构建更复杂的链。
langchain.chain.llm.LLMChain
|
源码片段:
@deprecated(
since="0.1.17",
alternative="RunnableSequence, e.g., `prompt | llm`",
removal="1.0",
)
class LLMChain(Chain):
"""Chain to run queries against LLMs.
This class is deprecated. See below for an example implementation using
LangChain runnables:
.. code-block:: python
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_openai import OpenAI
prompt_template = "Tell me a {adjective} joke"
prompt = PromptTemplate(
input_variables=["adjective"], template=prompt_template
)
llm = OpenAI()
chain = prompt | llm | StrOutputParser()
chain.invoke("your adjective here")
Example:
.. code-block:: python
from langchain.chains import LLMChain
from langchain_community.llms import OpenAI
from langchain_core.prompts import PromptTemplate
prompt_template = "Tell me a {adjective} joke"
prompt = PromptTemplate(
input_variables=["adjective"], template=prompt_template
)
llm = LLMChain(llm=OpenAI(), prompt=prompt)
"""
LangChain中的内置“链”
考虑到进行大模型应用开发中可能会经常面临的问题和场景,LangChain提供了一些内置链。
基础场景1:包含提示模板、根据用户输入填充模板、把格式化的提示传入模型、返回LLM的响应并对输出进行解析。基础的LLMChain提供了上述流程的接口。
基础场景2:获取一个调用的输出并用作另一个调用的输入。SequentialChain、SimpleSequentialChain可实现上述效果。
基础场景3:对输入文本进行一系列格式转换。TransformChain可通过设置转换函数完成批量文本格式转换。
基础场景4:通过调用LLM动态判断条件以确定后续调用哪一个目标Chain。
场景5:与API交互检索相关信息
Agents
LangChain 中的核心机制,通过“Agent”让大模型自主调用外部工具和内部工具.
可集成组件
对话模型(Chat Models)
检索器
工具集
如搜索、代码解释器
向量数据库
嵌入模型
……
对话模型
通义千问
环境准备:
pip install --upgrade --quiet dashscope
关于流式输出与工具调用官方文档已给出一个简单例子:https://python.langchain.com/docs/integrations/chat/tongyi/
下面给出一个简单非流式输出的例子
from langchain_community.chat_models.tongyi import ChatTongyi
from langchain_core.messages import HumanMessage, SystemMessage
os.environ["DASHSCOPE_API_KEY"] = api_settings.tongyi_api_key
chatLLM = ChatTongyi(streaming=False,
model_name=ModelTypeEnum.QWEN_TURBO_1101.value,
max_retries=3)
messages = [
SystemMessage(content="你是一个AI助手,你的名字是阿里妈妈"),
HumanMessage(content="介绍一下你自己")
]
res = chatLLM.invoke(messages)
print(res)
# output
content='你好!我是阿里妈妈,但在这里似乎出现了一个小误会。我是一个AI助手,由阿里云开发,我的名字其实是通义千问。作为AI助手,我的目标是帮助用户获得准确、有用的信息,解决他们的问题和困惑。我可以回答各种主题的问题,提供解释、建议和指导。请随时告诉我你需要什么帮助!'
- 需要注意:Tongyi类在遇到请求速率过高或模型权限不足时不会显式抛出真实错误,而是抛出一个KeyError异常。
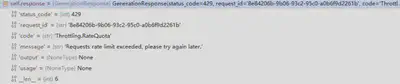
- …
Tongyi的qwen-turbo、qwen-plus、qwen-max等模型支持联网搜索,只需要启用enable_search参数即可实现RAG:
class ModelFactory:
@classmethod
def create_model(cls, model_type: str, enable_search: bool = True, max_retries=3):
return Tongyi(model=model_type,
max_retries=max_retries,
model_kwargs=dict(enable_search=enable_search, temperature=0.1))


Deepseek
检索器
LangChain内置了很多检索器,根据字符串形式的query输入,返回最“相关”的文档。
可查看BaseRetriever源码,了解这些检索器的接口定义。
class BaseRetriever(RunnableSerializable[RetrieverInput, RetrieverOutput], ABC):
"""Abstract base class for a Document retrieval system.
A retrieval system is defined as something that can take string queries and return
the most 'relevant' Documents from some source.
Usage:
A retriever follows the standard Runnable interface, and should be used
via the standard Runnable methods of `invoke`, `ainvoke`, `batch`, `abatch`.
Implementation:
When implementing a custom retriever, the class should implement
the `_get_relevant_documents` method to define the logic for retrieving documents.
Optionally, an async native implementations can be provided by overriding the
`_aget_relevant_documents` method.
Example: A retriever that returns the first 5 documents from a list of documents
.. code-block:: python
from langchain_core import Document, BaseRetriever
from typing import List
class SimpleRetriever(BaseRetriever):
docs: List[Document]
k: int = 5
def _get_relevant_documents(self, query: str) -> List[Document]:
\"\"\"Return the first k documents from the list of documents\"\"\"
return self.docs[:self.k]
async def _aget_relevant_documents(self, query: str) -> List[Document]:
\"\"\"(Optional) async native implementation.\"\"\"
return self.docs[:self.k]
Example: A simple retriever based on a scikit-learn vectorizer
.. code-block:: python
from sklearn.metrics.pairwise import cosine_similarity
class TFIDFRetriever(BaseRetriever, BaseModel):
vectorizer: Any
docs: List[Document]
tfidf_array: Any
k: int = 4
class Config:
arbitrary_types_allowed = True
def _get_relevant_documents(self, query: str) -> List[Document]:
# Ip -- (n_docs,x), Op -- (n_docs,n_Feats)
query_vec = self.vectorizer.transform([query])
# Op -- (n_docs,1) -- Cosine Sim with each doc
results = cosine_similarity(self.tfidf_array, query_vec).reshape((-1,))
return [self.docs[i] for i in results.argsort()[-self.k :][::-1]]
""" # noqa: E501
multi_query.MultiQueryRetriever
cohere_rag_retriever.CohereRagRetriever
wikipedia.WikipediaRetriever
bm25.BM25Retriever
……
工具集
向量数据库
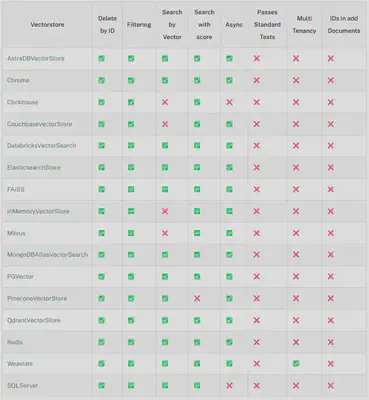
Qdrant
开源向量数据库和向量搜索引擎。
在LangChain中可轻松集成Qdrant,实现向量检索和RAG。
from langchain_community.vectorstores import Qdrant
from langchain_community.embeddings import OllamaEmbeddings
vectorstore = Qdrant.from_documents(
documents=chunked_documents, # 以分块的文档
embedding=OllamaEmbeddings(model="bge-m3:567m"), # 用BGE m3量化版本的Embedding Model做嵌入
location=":memory:", # in-memory 存储
collection_name="flower_documents",) # 指定collection_name
print(vectorstore.collection_name)
print(vectorstore.distance_strategy)
嵌入模型
基于LangGraph进行Agent开发
开发运维工具
LLM可观测性:LangSmith
下游任务资料
- 文档问答:https://huggingface.co/tasks/document-question-answering
相关学习资源
教程
- https://platform.openai.com/docs/guides/gpt-best-practices/gpt-best-practices
- LangChain for LLM Application Development - DeepLearning.AI