ElasticSearch查询的一些场景、方法、FAQs随笔
Table of Contents
ElasticSearch查询的一些场景、方法、FAQs随笔
Kibana
查询语句
注:以下随笔更侧重从查询场景划分,而非DSL语法层面划分。
搜索词
查询字符串
- 默认字段搜索
GET /news_detail1/_search?q=西门子医疗
- 短语搜索
GET /news_detail1/_search?q="西门子医疗"
ES行为分析:
如果没有指定特定的字段,Elasticsearch 将在所有默认字段中进行搜索。这些默认字段通常包括:
_all字段(如果已配置)。在较新的版本中,这个概念已经被废弃,转而支持更灵活的映射定义。- 所有文本类型字段(text fields),除非明确排除。
你可以通过修改索引映射来设置哪些字段应该包含在默认搜索范围内。
对于查询字符串来说,只要有一个索引字段命中搜索词即返回文档。
在查询中使用了双引号 "西门子医疗",这告诉 Elasticsearch 只返回那些包含完全匹配短语 “西门子医疗” 的文档。这意味着在这两个词之间不允许插入其他词语,并且顺序也必须一致。
指定某些字段搜索
GET /news_detail1/_search
{
"query": {
"multi_match": {
"query": "西门子医疗",
"fields": ["title"],
"type": "best_fields",
"operator": "and"
}
}
}
multi_match查询
fields字段指定要查询的字段
type参数指定如何处理多个字段的匹配,影响搜索的行为和结果相关性评分
best_fields
most_fields
cross_fields
适用于在多个字段中搜索同一个词的不同部分的情况。
Elasticsearch 将尝试跨字段匹配查询字符串中的每一个词,然后组合这些匹配来计算最终得分。
特别适合于名字、地址等跨越多个字段的信息搜索。
phrase
执行短语匹配。
要求查询字符串作为一个整体出现在至少一个字段中,保持词序不变。
对于需要精确匹配短语的场景非常有用。
phrase_prefix
类似于
phrase,但允许最后一个词作为前缀匹配。这意味着如果你输入的部分词语,Elasticsearch 可以返回以该部分词语开头的所有可能匹配的结果。
非常适合自动完成或建议功能。
Elasticsearch 将尝试跨字段匹配查询字符串中的每一个词,然后组合这些匹配来计算最终得分。
特别适合于名字、地址等跨越多个字段的信息搜索。
Elasticsearch 将尝试跨字段匹配查询字符串中的每一个词,然后组合这些匹配来计算最终得分。
特别适合于名字、地址等跨越多个字段的信息搜索。
特别适合于名字、地址等跨越多个字段的信息搜索。
选择哪种类型的
multi_match查询主要取决于具体需求:- 如果你想要找到单个字段内的最佳匹配,请使用
best_fields。 - 如果你在寻找的是不同字段间的内容相似性,请考虑
most_fields。 - 当你需要在多个字段中搜索同一个词的不同部分时,
cross_fields是理想的选择。 - 对于需要精确短语匹配的场合,
phrase和phrase_prefix分别提供了完整的短语匹配和基于前缀的短语匹配能力。
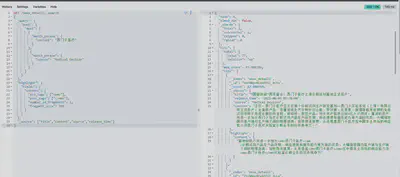
要求多个字段同时命中
GET /news_detail1/_search
{
"query": {
"bool": {
"must": [
{
"match_phrase": {
"content": "西门子医疗"
}
},
{
"match_phrase": {
"source": "Medical Devices"
}
}
]
}
},
"highlight": {
"fields": {
"content": {
"pre_tags": ["<em>"],
"post_tags": ["</em>"],
"number_of_fragments": 1,
"fragment_size": 100
}
}
},
"_source": ["title","content","source","release_time"]
}
要求单个字段同时命中某些词
GET /news_detail1/_search
{
"query": {
"bool": {
"must": [
{
"match_phrase": {
"content": "华为"
}
},
{
"match_phrase": {
"content": "三折叠"
}
},
{
"match_phrase": {
"content": "遥遥领先"
}
}
]
}
}
}
华为
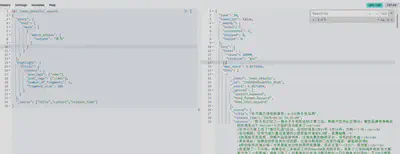
华为, 三折叠
- 华为, 三折叠, 遥遥领先
- 华为, 三折叠, 爱国
- 艾尔登法环,任天堂,升级,发布
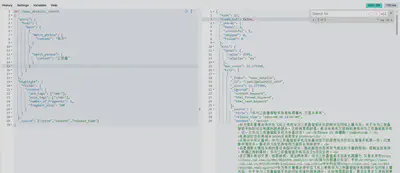
要求某些字段命中某些字段不命中的结果
从业务视角(产品经理/运营视角)出发,有时我们需要找到那些:
- 正文内容中提到了“西门子医疗”,
- 但标题中没有提到这个词的文章。
这可以用于发现:
- 标题起得不够精准的内容;
- 内容质量高但标题没优化的文章;
- 或者做内容质量分析时排除“标题党”。
假设有3条数据:
| news_id | title | content | 是否命中? |
|---|---|---|---|
| 1 | 医疗科技最新动态 | 西门子医疗推出了新的影像诊断系统 | ✅ 命中 |
| 2 | 西门子医疗发布新设备 | 西门子医疗推出新一代CT扫描仪 | ❌ 不命中(title也命中了) |
| 3 | AI助力医学发展 | 人工智能正在改变医疗行业 | ❌ 不命中(content也不命中) |
只有第 1 条会被这个查询返回。
查询DSL:
GET /news_detail1/_search
{
"from": 0,
"size": 10,
"query": {
"bool": {
"must": [
{
"match_phrase": {
"content": "西门子医疗"
}
}
],
"must_not": [
{
"match_phrase": {
"title": "西门子医疗"
}
}
]
}
},
"sort": [
{
"release_time": {
"order": "desc"
}
}
],
"_source": ["news_id", "title", "content", "source", "release_time"]
}
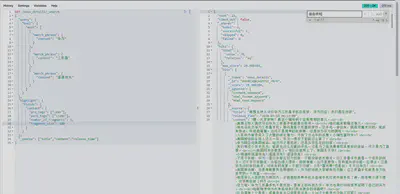
如果希望支持模糊搜索:
GET /news_detail1/_search
{
"from": 0,
"size": 10,
"query": {
"bool": {
"must": [
{
"match": {
"content": {
"query": "塞尔达传说王国之泪",
"operator": "and",
"fuzziness": "AUTO" // 启用自动模糊匹配
}
}
}
],
"must_not": [
{
"match_phrase": {
"title": "塞尔达"
}
}
]
}
},
"sort": [
{
"release_time": {
"order": "desc"
}
}
],
"_source": ["news_id", "title", "content", "source", "release_time"]
}
按时间范围过滤结果
GET /news_detail1/_search
{
"from": 0,
"size": 10,
"query": {
"bool": {
"must": [
{
"match": {
"title": {
"query": "西门子医疗",
"operator": "and"
}
}
},
{
"range": {
"release_time": {
"gte": "2025-03-01",
"lte": "2025-03-31",
"format": "yyyy-MM-dd"
}
}
}
]
}
},
"sort": [
{
"release_time": {
"order": "desc"
}
}
],
"_source": ["news_id", "title", "release_time"]
}
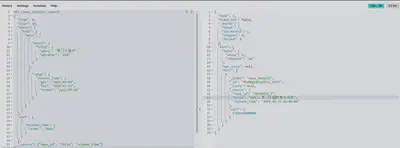
搜索结果排序
按时间排序
GET /news_detail1/_search
{
"query": {
"multi_match": {
"query": "西门子医疗",
"fields": ["title"],
"operator": "and" // 所有词都必须出现在至少一个字段中
}
},
"sort": [
{
"release_time": {
"order": "asc" // 按 release_time 字段升序排列
}
}
],
"_source": ["news_id", "title","content", "crawl_time", "source", "html_format", "release_time"] // 只返回指定的字段
}
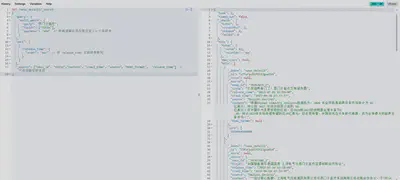
排序并分页
from
size
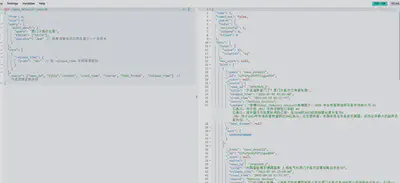
复杂查询
精确匹配、模糊匹配与时间衰减查询组合结果集
示例:
GET /news_detail1/_search
{
"query": {
"bool": {
"must": [
{
"exists": {
"field": "release_time"
}
}
],
"should": [
{
"function_score": {
"query": {
"match_phrase": {
"title": {
"query": "桌游",
"boost": 20 // 明确强调phrase的相关性
}
}
},
"functions": [
{
"gauss": {
"release_time": {
"origin": "now",
"scale": "10d",
"offset": "0d"
}
}
}
],
"score_mode": "sum",
"boost_mode": "multiply"
}
},
{
"function_score": {
"query": {
"multi_match": {
"query": "桌游",
"fields": ["title^20.0", "content^1.0"],
"operator": "and"
}
},
"functions": [
{
"gauss": {
"release_time": {
"origin": "now",
"scale": "10d",
"offset": "0d"
}
}
}
],
"score_mode": "sum",
"boost_mode": "multiply"
}
}
],
"minimum_should_match": 1
}
},
"_source": ["news_id", "title", "source", "release_time"]
}

多查询条件布尔关系组合结果集
同时匹配西门子医疗、联影医疗、人工智能三个关键词,且title字段不包含战略合作关键词的结果集
"query": { "bool": { "should": [ { "multi_match": { "query": "西门子医疗 联影医疗", "fields": ["title", "content"], "type": "phrase" } }, { "match_phrase": { "content": "人工智能" } } ], "must_not": [ { "match_phrase": { "title": "王文斌" } } ] } }
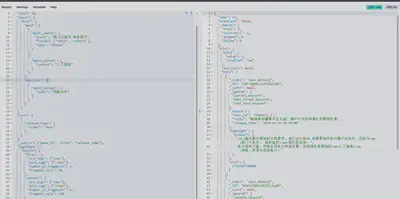
多个bool查询条件的并集,其中每个bool查询条件内需精确匹配某短语且排除/包含某短语
示例dsl片段:
"query": { "bool": { "should": [ { "bool": { "must": [ { "match_phrase": { "title": "Agent" }} ], "must_not": [ { "match_phrase": { "title": "通义千问" }} ] } }, { "bool": { "must": [ { "match_phrase": { "title": "GPT" }} ], "must_not": [ { "match_phrase": { "title": "OpenAI" }} ] } } ], "minimum_should_match": 1 } }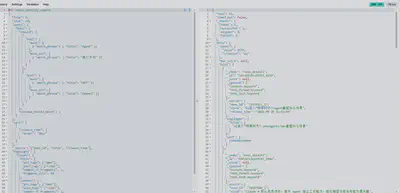
示例dsl片段:
"query": {
"bool": {
"should": [
{
"bool": {
"must": [
{ "match_phrase": { "title": "向量数据库" }
},
{ "match_phrase": { "title": "Agent" }}
]
}
},
{
"bool": {
"must": [
{ "match_phrase": { "title": "GPT" }
},
{
"match_phrase": { "title": "智能体" }
}
]
}
}
],
"minimum_should_match": 1
}
}
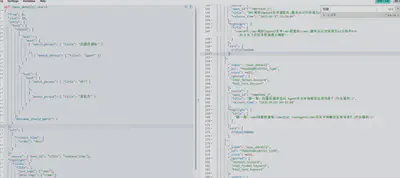
- 使用filter精确过滤结果集
GET /news_detail1/_search
{
"query": {
"bool": {
"must": [
{
"exists": {
"field": "release_time"
}
}
],
"should": [
{
"function_score": {
"query": {
"match_phrase": {
"title": {
"query": "必维集团",
"boost": 3
}
}
},
"functions": [
{
"gauss": {
"release_time": {
"origin": "now",
"scale": "60d",
"offset": "30d",
"decay": 0.8
}
}
}
],
"score_mode": "sum"
}
},
"filter": {
"term": {
"source.keyword": "BV必维国际GSIT"
}
},
"minimum_should_match": 1
}
},
"_source": ["news_id", "title", "release_time", "source"],
"explain": true
}
- ……
自定义评分函数
# Perform a search in my-index
POST /news_detail1/_search
{
"from": 0,
"size": 10,
"_source": ["news_id", "title", "content", "release_time", "crawl_time","source"],
"query": {
"bool": {
"must": [
{
"function_score": {
"query": {
"multi_match": {
"query": "西门子医疗",
"fields": ["title^5.0", "content^1.0"],
"operator": "and"
}
},
"functions": [
{
"gauss": {
"release_time": {
"origin": "2025-05-29",
"scale": "10d",
"offset": "0d"
}
}
}
],
"score_mode": "sum",
"boost_mode": "multiply"
}
},
{
"exists": {
"field": "release_time"
}
}
]
}
}
}
ES查询优化
底层原理
了解ES查询底层原理对与分析查询性能瓶颈必不可少.
数据结构
倒排索引
doc_values
查询过程底层数据流
数据结构
倒排索引
(暂略)
doc_values
doc_values字段是一个磁盘上的数据结构,它在文档索引时构建,支持高效的数据访问。它存储与_source相同的值,但采用列式存储,以便更有效地进行排序和聚合。
除了text和annotated_text文本外,绝大部分字段类型支持doc values。doc values默认是被启用的.
数值类型(numeric types)
日期类型(date types)
布尔类型(boolean types)
ip类型(ip type)
地理坐标类型(geo point type)
关键字类型(keyword type)
更多详情(如如何禁用doc values),请参考官方文档:doc_values | Elastic Documentation
优化方法(实操)
索引映射分析
_mapping
评分方法
explain
分词器
_analyze
AI搜索
索引映射分析
GET /INDEX_NAME/_mapping
评分方法
默认评分机制
BM25
自定义评分机制
boost: 提升某个字段或查询条件的权重
function_score
functions
weight
random_score:生成随机得分;适用于随机抽样场景(如随机推荐、换一批)
field_value_factor: 使用字段值进行计算得分
script_score
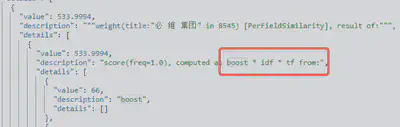
分数计算模式
scode_mode
boost_mode
decay function
The Closer, The Better | Elasticsearch: The Definitive Guide [2.x] | Elastic
$score = exp^{-0.5 (\frac{max(|doc_value - origin| - offset, 0) }{ scale})^2}$
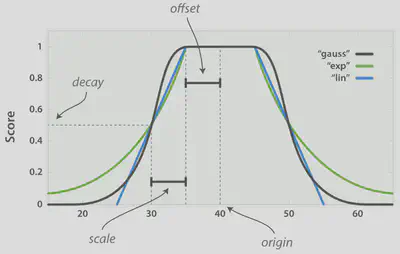
想提高最近时间新闻的分数,可以在控制其它变量的情况下设置较小的offset和较大的scale,使超出scale和offset时间的分数时间衰减因子急速下降: [ps: 对最近定义得越窄,offset应该设置得越小;否则越大]
测试基准0:无时间距离因子衰减

对比1:10d scale, 3d offset, decay 0.8

对比2:100d scale, 3d offset, decay 0.8

Learn To Rank
RRF
分词器
分词器效果分析
分析分词器效果
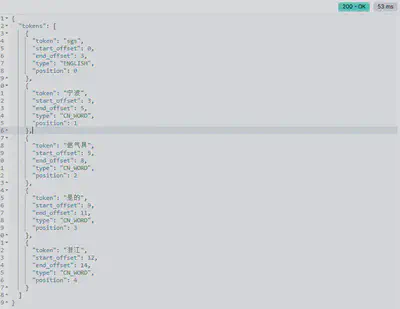
POST /_analyze
{
"analyzer": "whitespace",
"text": "SGS宁波燃气具 是的在浙江"
}
analyzer参数选项:
- standard
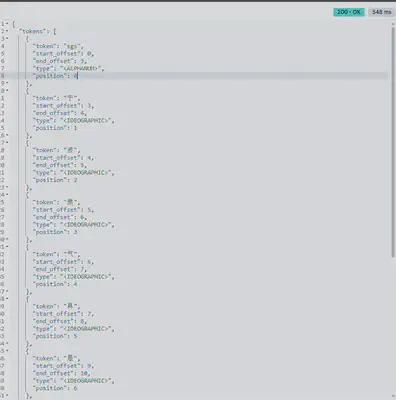
- whitespace
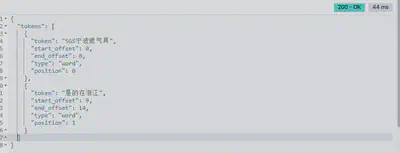
- ik_max_word:最细粒度的中文分词拆分
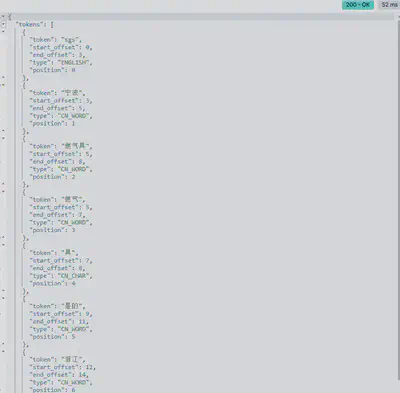
- ik_smart: 最粗粒度的中文分词拆分
- ……
分析字段的分词规则
分析指定字段映射规则
POST /INDEX_NAME/_analyze
{
"field": "title",
"text": "SGS宁波燃气具"
}

POST /INDEX_NAME/_analyze
{
"field": "title",
"text": "矩阵起源vs华为云二次方根本不知道"
}
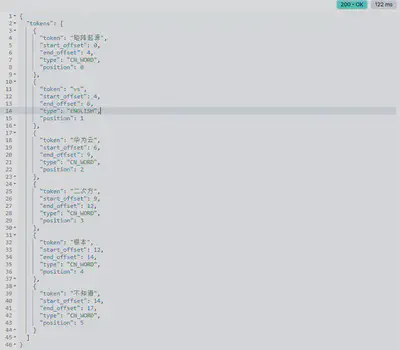
查看指定字段的分词器
GET /news_detail1/_mapping
向量查询
向量类型字段
向现有索引添加向量字段:
PUT /news_detail1_vector/_mapping
{
"properties": {
"title_vector": {
"type": "dense_vector",
"dims": 1024
}
}
}
FAQs
Elasticsearch 是否支持全局相关性排序,局部(分页) 按时间/其它数值型字段排序?
Elasticsearch 是全局排序再分页的,并不会在分页后再按字段局部排序。
如果需要实现局部排序,你可以:
用
_score排序(全局相关性优先)一次拉取一页(比如 20 条)
在前端对这 20 条结果再按时间
release_time desc排一次
……
资料参考
基本
ES详解 - 优化:ElasticSearch性能优化详解 | Java 全栈知识体系
评分
The Closer, The Better | Elasticsearch: The Definitive Guide [2.x] | Elastic
Using Decay Function (Gauss) - ElasticSearch
进阶
全球下载量最大的向量数据库:Elasticsearch | Elastic
阿里云AI搜索方案_检索分析服务 Elasticsearch版(ES)-阿里云帮助中心
https://www.elastic.co/search-labs/tutorials/search-tutorial/vector-search/hybrid-search