字节开源Deerflow项目体验与分析
本地部署
系统部署
依赖安装
uv sync
- ppt生成
npm install -g @marp-team/marp-cli
配置修改
https://github.com/bytedance/deer-flow/blob/main/docs/configuration_guide.md
conf.yaml
.env
主要配置LLM、搜索工具的API或key。
Docker部署
docker build -t deer-flow-api .
有时候构建过程包安装或基础镜像拉取失败,与网络代理有关系,可切换代理尝试。
docker compose build && docker compose up -d
功能体验
Deep Research
本地部署版本功能体验上时发现的问题:
博客功能无法正常使用
要求生成PPT,但不会生成
未能统一语言(主要与模型能力有关,如doubao lite系列会出现该问题)
- 幻觉?

旅游行程规划
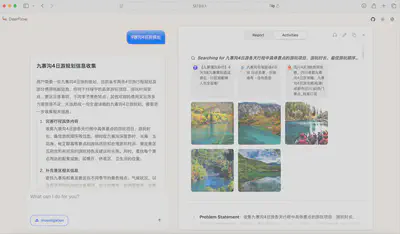
香港长洲岛1 - 2日无住宿旅行规划信息收集


市场调研

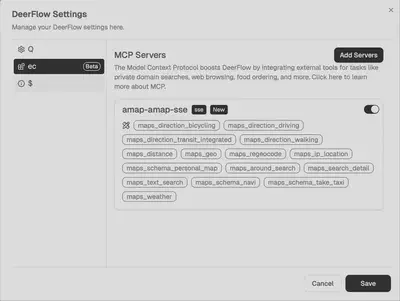
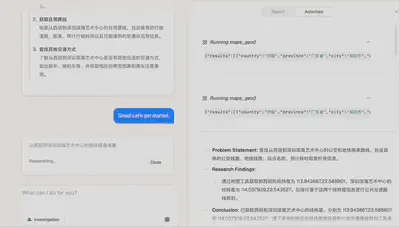
外部MCP接入
高德地图MCP
项目结构分析
源码分析
结构分析(基于Cursor辅助)
分析这个项目的架构:
整体架构
- 这是一个前后端分离的项目,采用 Python 后端 + Next.js 前端的架构
- 使用 Docker 进行容器化部署
- 支持多语言(有多个语言的 README 文件)
后端架构 (src/)
agents/: 智能代理模块llms/: 大语言模型相关实现tools/: 工具集crawler/: 爬虫模块utils/: 通用工具函数prompts/: 提示词模板graph/: 图相关功能config/: 配置文件server/: 服务器相关代码podcast/: 播客相关功能prose/: 文本处理相关ppt/: PPT 相关功能
前端架构 (web/)
- 使用 Next.js 框架
- 采用 TypeScript 开发
- 包含完整的开发工具链配置(ESLint, Prettier, PostCSS)
- 使用 pnpm 作为包管理器
项目工具链
- 使用
pyproject.toml管理 Python 依赖 - 使用
Makefile进行构建和部署 - 包含 Docker 和 docker-compose 配置
- 包含 pre-commit 钩子进行代码检查
- 使用
文档和测试
docs/: 项目文档tests/: 测试用例examples/: 示例代码- 多语言文档支持(README_*.md)
开发工具支持
- VS Code 配置 (.vscode/)
- GitHub Actions 配置 (.github/)
- 代码格式化配置
部署相关
- Docker 支持
- 环境配置文件 (conf.yaml)
- 启动脚本 (bootstrap.sh/bat)
这个项目看起来是一个复杂的 AI 应用系统,集成了多种功能模块,包括:
- 大语言模型集成
- 智能代理系统
- 爬虫功能
- 播客处理
- PPT 生成
- 文本处理
- Web 界面
项目采用了现代化的开发实践,包括:
- 容器化部署
- 完整的开发工具链
- 多语言支持
- 自动化测试
- 代码质量控制
这是一个企业级的项目,具有良好的工程实践和完整的开发基础设施。
Agent设计架构
结合项目中的相关代码,关于 agent 的设计可以总结如下:
1. agent 的核心设计
- agent 的创建由
src/agents/agents.py中的create_agent工厂函数负责。 - 该函数通过
create_react_agent(来自 langgraph)创建 agent,并统一配置模型、工具和提示词模板。
代码核心逻辑
def create_agent(agent_name: str, agent_type: str, tools: list, prompt_template: str):
return create_react_agent(
name=agent_name,
model=get_llm_by_type(AGENT_LLM_MAP[agent_type]),
tools=tools,
prompt=lambda state: apply_prompt_template(prompt_template, state),
)
- agent_name:agent 的名称
- agent_type:agent 类型(如 basic、reasoning、vision)
- tools:该 agent 可用的工具列表
- prompt_template:提示词模板名称
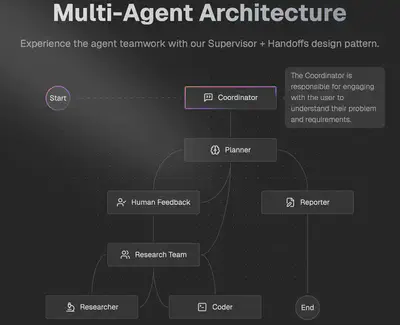
多Agent工作流(核心亮点)
过 src/graph/builder.py 构建 StateGraph,定义了如下节点:
coordinator(协调者):与用户交互,决定是否需要规划。
background_investigator(背景调查):调用搜索工具进行信息检索。
planner(规划者):生成任务计划。
human_feedback(人工反馈):支持用户对计划的中断、编辑、接受。
research_team(研究团队):分发任务给 researcher/coder。
researcher(研究员):负责信息检索、资料收集。
coder(程序员):负责代码实现、数据处理。
reporter(报告员):撰写最终报告。
智能体节点实现
每个节点为一个函数,输入为当前 State,输出为 Command(可包含状态更新、跳转下一个节点等)。
节点间通过 goto 字段流转,支持条件分支、循环、人工中断。
智能体通过工厂方法 create_agent 动态创建,注入不同 LLM、工具和提示词。
planner
主要功能
负责根据用户输入和背景调查结果,生成完整的任务计划(Plan)。
支持多轮规划(plan_iterations),并根据人工反馈调整计划。
判断计划是否足够完善,决定是否进入报告环节或需要进一步细化。
关键实现
读取当前状态中的历史消息、计划轮数、背景调查结果等,构造 prompt。
首轮规划时会将背景调查结果拼接到 prompt,辅助 LLM 生成更有针对性的计划。
通过 get_llm_by_type 获取对应 LLM,调用 .with_structured_output(Plan) 强制输出结构化 JSON。
如果计划轮数超过最大值,直接进入 reporter 节点。
对 LLM 输出做 JSON 修复和解析,若解析失败则根据轮数决定是否终止或重试。
判断 has_enough_context 字段,决定是否进入报告节点或等待人工反馈。
background_investigation_node
主要功能
在规划前对用户问题进行外部信息检索,为后续规划提供数据支撑。
支持多种搜索引擎(如 Tavily、DuckDuckGo 等),可扩展性强。
将检索结果结构化存储,便于后续节点引用。
关键实现
读取用户最新消息,调用配置的搜索工具(如 Tavily)。
检查搜索结果格式,若为列表则提取 title 和 content,否则记录错误日志。
将检索结果以 JSON 字符串形式存入 state[“background_investigation_results”]。
跳转到 planner 节点,辅助生成更有依据的计划。
research_team_node
def research_team_node(
state: State,
) -> Command[Literal["planner", "researcher", "coder"]]:
"""Research team node that collaborates on tasks."""
logger.info("Research team is collaborating on tasks.")
current_plan = state.get("current_plan")
if not current_plan or not current_plan.steps:
return Command(goto="planner")
if all(step.execution_res for step in current_plan.steps):
return Command(goto="planner")
for step in current_plan.steps:
if not step.execution_res:
break
if step.step_type and step.step_type == StepType.RESEARCH:
return Command(goto="researcher")
if step.step_type and step.step_type == StepType.PROCESSING:
return Command(goto="coder")
return Command(goto="planner")
## 3. research_team_node(研究团队节点)
主要功能
负责根据当前计划的步骤,分发任务给 researcher(研究员)或 coder(程序员)。
判断每个步骤的类型(RESEARCH/PROCESSING),动态分配给不同 agent。
检查所有步骤是否已完成,决定是否需要重新规划。
关键实现
读取 current_plan,遍历 steps,查找第一个未完成的步骤。
根据 step_type 跳转到 researcher_node 或 coder_node。
如果所有步骤都已完成,或计划为空,则跳转回 planner 重新生成计划。
通过 Command(goto=…) 实现节点间跳转。
human_feedback
(1)判断是否自动接受计划
读取 state[“auto_accepted_plan”],如果为 True,则跳过人工审核,直接进入后续流程。
如果为 False,则进入人工审核环节。
(2)人工审核环节
调用 feedback = interrupt(“Please Review the Plan."),中断流程,等待用户操作(如在前端弹窗让用户选择“编辑计划”或“接受计划”)。
根据用户反馈内容分三种情况处理:
[EDIT_PLAN]:用户选择“编辑计划”,则将反馈内容作为新消息加入,跳转回 planner 节点,重新生成计划。
[ACCEPTED]:用户选择“接受计划”,流程继续。
其他情况:抛出异常,提示反馈类型不支持(防止协议被破坏)。
(3)计划被接受后的处理
读取当前计划、计划轮数(plan_iterations)。
尝试修复并解析当前计划(repair_json_output + json.loads),防止 LLM 输出格式异常导致流程崩溃。
计划轮数自增,记录本次审核通过。
判断计划是否有足够上下文(has_enough_context),如果有则直接跳转到 reporter 节点生成最终报告,否则进入 research_team 节点继续任务分解与执行。
(4)异常处理
- 如果计划解析失败(JSONDecodeError),且已多次尝试,则直接进入 reporter 节点,否则流程终止。
(5)状态更新与跳转
更新 current_plan(结构化 Plan 对象)、plan_iterations、locale。
跳转到下一个节点(planner、research_team、reporter 或 __end__)
可改进
用户反馈类型可扩展:目前只支持“编辑/接受”,可扩展为“拒绝/跳过/部分接受”等更丰富的操作。
异常提示更友好:对于不支持的反馈类型,建议给出更明确的用户提示而非直接抛异常。
前端交互优化:配合前端可实现更丰富的交互体验,如计划对比、历史版本回溯等。
计划内容校验:可增加计划内容的结构和语义校验,进一步提升健壮性。
reporter_node
(1)获取当前计划与上下文
通过 state.get(“current_plan”) 获取当前的研究计划(Plan),包括任务标题、描述、步骤等。
通过 state.get(“locale”) 获取当前语言环境(如英文、中文)。
(2)构造 LLM 输入消息
首先将计划的标题和描述以结构化 Markdown 形式包装,作为 HumanMessage 传递给大模型。
使用 apply_prompt_template(“reporter”, input_),进一步补充和格式化 prompt,确保 LLM 能理解输出要求。
# Research Requirements\n\n
## Task\n\n
{current_plan.title}\n\n
## Description\n\n
{current_plan.thought}
(3)注入系统级写作规范
IMPORTANT: Structure your report according to the format in the prompt. Remember to include:\n\n
1. Key Points - A bulleted list of the most important findings\n
2. Overview - A brief introduction to the topic\n
3. Detailed Analysis - Organized into logical sections\n
4. Survey Note (optional) - For more comprehensive reports\n
5. Key Citations - List all references at the end\n\nFor citations, DO NOT include inline citations in the text. Instead, place all citations in the 'Key Citations' section at the end using the format: `- [Source Title](URL)`. Include an empty line between each citation for better readability.\n\n
PRIORITIZE USING MARKDOWN TABLES for data presentation and comparison. Use tables whenever presenting comparative data, statistics, features, or options. Structure tables with clear headers and aligned columns. Example table format:\n\n
| Feature | Description | Pros | Cons |\n|---------|-------------|------|------|\n
| Feature 1 | Description 1 | Pros 1 | Cons 1 |\n
| Feature 2 | Description 2 | Pros 2 | Cons 2 |,
追加一条 system 级别的 HumanMessage,强制要求输出结构化报告,包括:
关键要点(Key Points,项目符号列表)
概述(Overview)
详细分析(Detailed Analysis,分节)
调查说明(Survey Note,可选)
关键引用(Key Citations,全部放在文末,禁止正文内引用)
优先使用 Markdown 表格 展示对比、数据等内容,并给出表格示例
(4)整合研究过程中的观察结果
Below are some observations for the research task:\n\n
{observation}",
- 遍历 state.get(“observations”, []),将每个 observation 作为单独的 HumanMessage 追加到 prompt,确保 LLM 能参考所有中间产出。
(5)调用 LLM 生成报告
通过 get_llm_by_type(AGENT_LLM_MAP[“reporter”]) 获取 reporter 专用 LLM(通常为 basic 类型)。
调用 .invoke(invoke_messages),将所有消息输入 LLM,生成最终报告。
(6)日志与返回
记录输入和输出日志,便于后期排查和优化。
返回字典 {“final_report”: response_content},供后续流程或前端展示。
可改进建议
异常处理:当前未对 LLM 调用失败、内容为空等情况做健壮性处理,建议增加异常捕获和兜底提示。
内容长度控制:对于 observation 很多或计划很长的情况,建议对输入做截断或摘要,防止 prompt 超长导致 LLM 失效。
多格式输出:可支持导出 PDF、HTML 等多种格式,便于后续使用。
自定义模板:允许用户自定义报告模板和结构,提升灵活性。
多语言完善:根据 locale 自动切换提示词和输出语言,提升国际化体验。
2. agent 与 LLM 的映射
- agent 类型与 LLM 类型的映射关系由
src/config/agents.py的AGENT_LLM_MAP决定。 - 目前所有 agent 默认都用 “basic” 类型的 LLM,但设计上支持不同 agent 用不同 LLM。
AGENT_LLM_MAP: dict[str, LLMType] = {
"coordinator": "basic",
"planner": "basic",
...
}
3. LLM 的获取与管理
- LLM 的实例由
src/llms/llm.py的get_llm_by_type提供,支持缓存,避免重复初始化。 - LLM 的具体配置(如模型参数、API key 等)从
conf.yaml读取,支持多种 LLM 类型(basic、reasoning、vision)。
4. agent 的提示词模板
- agent 的 system prompt 由
src/prompts/template.py的apply_prompt_template动态渲染,支持 Jinja2 变量替换。 - 这样每个 agent 可以有独立的提示词模板,且能根据当前状态动态生成 prompt。
5. agent 的扩展性
- 只需在
AGENT_LLM_MAP增加新 agent 类型,并在conf.yaml配置对应 LLM,即可扩展 agent。 - 工具(如搜索、TTS、爬虫、代码执行)可灵活注入到 agent,支持多服务器/多工具配置(MCP)。
总结优劣
分析agent节点源码,指出其值得学习和改进的地方
一、agent节点源码分析(以src/graph/nodes.py为主)
1. 节点结构与职责分明
每个 agent 节点(如 coordinator_node、planner_node、researcher_node、coder_node、reporter_node 等)均为独立函数,输入为 State(全局状态),输出为 Command(包含状态更新和下一个节点跳转),职责清晰,便于维护和扩展。
2. 多智能体协作流程
- coordinator_node:负责与用户交互,决定是否需要规划、是否先做背景调查。
- background_investigation_node:调用搜索工具,获取外部信息,增强后续规划的上下文。
- planner_node:根据当前信息生成详细计划,支持多轮规划和人工反馈。
- human_feedback_node:支持用户对计划的中断、编辑、接受,体现“人机协作”。
- research_team_node:根据计划分发任务给 researcher/coder,支持多步任务协作。
- researcher_node/coder_node:分别负责信息检索/代码实现,支持工具注入和多服务器扩展。
- reporter_node:汇总结果,生成最终报告,强调结构化输出和引用规范。
3. 工具与 LLM 解耦
- agent 节点通过
create_agent工厂方法动态注入 LLM 和工具,支持不同 agent 绑定不同模型和工具,便于扩展和测试。 - MCP 工具机制支持多服务器、多工具动态注册,提升了系统的灵活性和可扩展性。
4. 状态管理与流程跳转
- 所有节点通过
State对象共享上下文,支持多轮信息累积、计划迭代、结果追踪。 - 节点间通过
goto字段实现灵活跳转,支持条件分支、循环、终止等复杂流程。
5. 代码风格与可读性
- 代码结构清晰,注释详细,函数粒度适中,便于理解和二次开发。
- 日志记录较为充分,便于后期排查问题。
二、值得学习的地方
多智能体分工协作的设计模式
每个 agent 节点职责单一,流程清晰,极大提升了系统的可维护性和可扩展性。人机协作与人工反馈机制
支持用户中断、编辑、接受计划,体现了“人机共创”的理念,适合复杂任务场景。工具链与 LLM 解耦
工具和大模型通过工厂方法动态注入,便于后续扩展新工具或切换模型。流程状态统一管理
通过 State 对象贯穿全流程,支持多轮上下文、计划、结果的统一管理。结构化输出与引用规范
报告节点强制结构化输出和引用格式,提升了结果的可读性和可追溯性。
三、可以改进的地方
异常处理与健壮性
- 某些节点(如 planner/human_feedback)对 JSON 解析失败的处理较为简单,建议增加更细致的错误提示和恢复机制,避免流程直接终止。
- MCP 工具调用、外部 API 调用等缺乏超时、重试、降级等健壮性设计。
流程可观测性与调试
- 虽有日志,但缺乏结构化、分布式追踪,建议引入 trace id、链路追踪、流程可视化等工具,便于复杂流程调试和性能分析。
测试覆盖与模拟
- 目前未见自动化测试和 mock 机制,建议为每个 agent 节点编写单元测试和集成测试,提升系统稳定性。
安全性与权限控制
- MCP 工具和代码执行相关节点缺乏沙箱和权限隔离,建议增加安全校验和资源限制,防止被恶意利用。
配置与热更新能力
- agent、工具、LLM 的配置需重启服务才能生效,建议支持热加载和动态切换,提升运维效率。
节点间依赖与解耦
- 某些节点对 State 字段依赖较强,建议增加字段校验和默认值,避免因上游节点异常导致下游崩溃。
多语言与国际化
- locale 字段已支持多语言,但实际 prompt、输出等国际化支持有限,建议进一步完善。
值得学习:多智能体分工协作、人机共创、工具链解耦、流程状态管理、结构化输出。
建议改进:异常健壮性、流程可观测性、测试覆盖、安全隔离、配置热更新、节点解耦、多语言支持。
如需针对某个 agent 节点的详细优化建议,可进一步指定节点名称。
问题
根据你提供的源码结构和部分实现,结合主流多智能体/大模型项目的最佳实践,DeerFlow 项目当前可能存在或潜在的问题主要有以下几个方面:
- 多智能体流程复杂度高,调试与可观测性不足
- 多智能体(coordinator、planner、researcher、coder、reporter 等)通过 LangGraph 串联,流程分支多,状态转移复杂,缺乏详细的流程可视化和调试工具,一旦某节点出错或状态异常,排查难度较大。
- 日志虽然有,但粒度和结构化程度有限,缺少分布式追踪和详细的执行链路记录。
- 配置与环境依赖分散,易出错
- LLM、工具、API Key、MCP 等配置分散在 conf.yaml、环境变量、代码多处,缺乏统一的配置校验和加载机制,容易因配置遗漏或格式错误导致服务启动失败或功能异常。
- 例如 TTS、LLM、MCP 工具等依赖外部服务,未检测到健壮的健康检查和降级机制。
- 多模型与多工具适配能力有限
- 当前 AGENT_LLM_MAP 仅支持 “basic” 类型,虽然有扩展接口,但实际多模型、多后端适配和热切换能力有限,如需支持多 LLM 或多工具动态切换,需进一步增强。
- MCP 工具集成虽有,但工具注册、权限、沙箱隔离等安全机制不明显。
- 用户交互与人工反馈流程不够友好
- human_feedback_node 支持人工中断和编辑,但前端与后端的交互协议和体验细节未见详细设计,如计划编辑、任务重试、异常恢复等场景处理不够完善。
- 流式接口(/api/chat/stream)异常时的错误提示和恢复机制不够健全。
- 测试覆盖与健壮性不足
- tests 目录未见详细内容,自动化测试、集成测试、回归测试覆盖率未知,多智能体协作流程极易因边界条件或输入异常导致崩溃。
- 缺乏 mock 工具和端到端测试脚本,难以保证复杂场景下的稳定性。
- 文档与开发者友好性有待提升
- 配置文件虽有注释,但缺乏详细的开发者文档、二次开发指南和常见问题排查手册。
- 多语言 README 丰富,但API 文档、流程图、架构图等技术文档不够直观。
- 安全性与权限控制薄弱
- 未见对外 API 的权限校验、速率限制、输入校验等安全措施,存在被滥用或攻击的风险。
- MCP 工具和代码执行相关接口,缺乏沙箱和资源隔离机制,有被恶意利用的隐患。
DeerFlow 项目架构先进,功能丰富,但由于多智能体协作和多工具集成的复杂性,当前主要问题集中在可观测性、配置健壮性、测试覆盖、安全性和开发者友好性等方面。
如需定位具体 bug 或优化建议,可进一步指定模块或提供运行日志、异常信息等。
除此之外,目前任务执行还未有持久化记录。
后端设计
1. 技术选型与基础架构
主框架:采用 FastAPI 作为 Web API 框架,具备高性能、异步支持、类型注解友好等优点。
多智能体编排:后端核心逻辑通过 LangGraph 进行多智能体流程编排,API 层负责与前端/外部系统交互,业务逻辑主要在 graph/agents 等模块。
2. 目录结构与接口分布
主要接口相关代码位于 src/server/ 目录,典型文件有:
app.py:FastAPI 应用主入口,定义所有 HTTP 路由。
chat_request.py:定义请求/响应的数据模型(Pydantic)。
mcp_request.py、mcp_utils.py:与多工具服务器(MCP)相关的接口和工具。
其他如 src/graph/、src/tools/、src/llms/ 等为业务逻辑和工具实现。
3. 主要接口设计
3.1 核心 API 路由
1)对话流式接口
@app.post("/api/chat/stream")
async def chat_stream(request: ChatRequest):
...
return StreamingResponse(
_astream_workflow_generator(...),
media_type="text/event-stream",
)
功能:驱动多智能体协作的主入口,支持流式返回,适合前端实时展示 agent 计划、执行、报告等多阶段结果。
实现:内部调用 _astream_workflow_generator,将请求参数(如消息、最大迭代次数、MCP 配置等)传递给多智能体编排引擎(LangGraph),并将每个阶段的结果以 SSE(Server-Sent Events)流式推送给前端。
2)文本转语音接口
@app.post("/api/tts")
async def text_to_speech(request: TTSRequest):
...
return Response(content=audio_data, media_type=f"audio/{request.encoding}", ...)
功能:将文本内容转为语音,返回音频文件。
实现:集成 Volcengine TTS 服务,参数通过环境变量和请求体传递,支持多种音色、语速、音量等自定义。
3)内容生成类接口
/api/podcast/generate
/api/ppt/generate
/api/prose/generate
功能:分别用于播客脚本、PPT、散文等内容的自动生成。
实现:每个接口对应不同的多智能体子流程,参数和返回结构类似。
4. 业务与编排解耦
API 层(如 app.py)只负责参数校验、请求分发和响应格式化,核心业务逻辑全部下沉到 graph/agents/tools 等模块,实现了接口与业务的解耦。
多智能体流程的状态管理、节点跳转、工具调用等全部在 graph 层完成,API 层只需关注输入输出。
4)MCP 工具服务器元数据接口
@app.post("/api/mcp/server/metadata")
async def mcp_server_metadata(request: MCPServerMetadataRequest):
...
- 功能:用于多工具服务器(MCP)的元数据获取和注册,支持多后端工具动态扩展。
3.2 数据模型与参数校验
所有接口参数均采用 Pydantic 数据模型(如 ChatRequest, TTSRequest),保证类型安全和自动文档生成。
支持复杂嵌套结构,便于描述多智能体协作所需的上下文、配置、历史消息等。
3.3 中间件与跨域支持
默认集成 CORS 中间件,允许所有来源跨域访问,便于前后端分离部署和第三方集成。
可根据实际需求收紧安全策略。
5. 扩展性与可维护性
新功能扩展:只需在 graph/agents 层增加新节点或工具,API 层可复用现有路由。
多模型/多工具支持:通过配置和 MCP 机制,支持多 LLM、多工具动态切换和扩展。
流式接口:主对话接口采用流式推送,极大提升了用户体验和系统响应性。
6. 典型调用流程示意
前端调用 /api/chat/stream,提交用户消息和配置。
API 层校验参数,调用多智能体编排引擎。
各 agent 节点(如 coordinator、planner、researcher、reporter)依次执行,状态在 State 中流转。
每个阶段的结果通过 SSE 流式推送给前端,前端实时渲染。
任务完成后,返回最终报告或内容。
7. 可改进建议
接口安全:目前所有接口对外开放,建议增加鉴权、速率限制等安全措施。
错误处理:流式接口异常时的错误提示和恢复机制可进一步完善。
接口文档:可集成 Swagger/OpenAPI 自动生成更详细的接口文档,便于第三方集成。
健康检查:建议增加 /health 或 /status 路由,便于运维监控。
总结
DeerFlow 后端接口架构清晰分层、解耦良好、扩展性强,通过 FastAPI 提供高性能 API 服务,核心业务逻辑全部下沉到多智能体编排层,支持流式对话、内容生成、TTS 等多种 AI 能力,适合复杂的自动化与人机协作场景。