对数据库表设计之组合条件筛选的思考与实验
简单数学原理,排列组合编码设计的艺术
背景
参与某个项目,需要实现对某个表的数据进行条件筛选,并且多个条件之间可以组合,如何设计表结构才能够高效地查询,避免用户等待过长时间?出于项目保密需求,本文将避开谈论项目过程的实际字段,基于模拟数据构造一个场景进行分析。
生成模拟数据
首先写个脚本,生成约一百万条记录,每条记录可能有1到m个标签。标签候选集如下:
战士
坦克
辅助
法师
射手
刺客
战略士
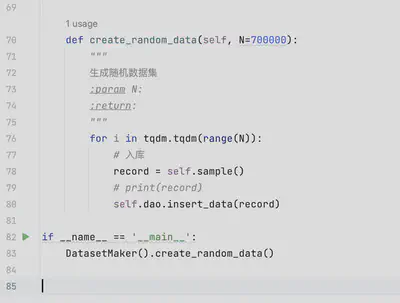

至此,可以开始测试不同sql查询方式的性能,查询面向的场景:根据标签过滤记录,需要注意的是,当按照“辅助、坦克、战士”来过滤记录时,需要返回包含这些标签的记录而不仅仅是精确匹配这三个标签的记录。
设计思路与评价
如何评价一种设计好不好,姑且从查询性能(数据量)、扩展灵活性两个指标来评判,这应该也是最基础最重要的两个指标。如果查询性能随数据量级数的增加下降趋势更缓、面对数据类别增加需求扩展更加灵活则认为设计更好。
以下是几种设计思路:
- first clue:通过一个onehot编码字段存储多标签组合信息,使用模糊查询(like)实现
- 简单暴力:分N个字段存储,每个字段分别存二元变量用于标记是否
- onehot编码存储,但使用位运算进行查询
- 设计排列组合编码表。
思路1:onehot编码表示多标签,通过模糊查询实现组合筛选
模拟场景,查询标签包含辅助、刺客的记录数,筛选条件编码(0010010)
示例SQL:针对onehot编码字段通过like模糊查询。
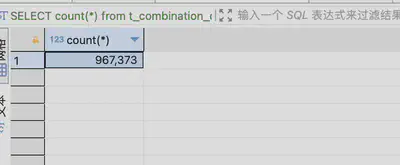
统计满足条件的记录数
可见针对当前的数据量,在未对tags_onehot_code建立索引的情况下,统计满足条件0010010的记录数耗时236ms,共有约37w条记录满足条件。
-- 无索引 236ms 368900
SELECT count(*) from t_combination_query_test tcqt WHERE tags_onehot_code like '__1__1_';
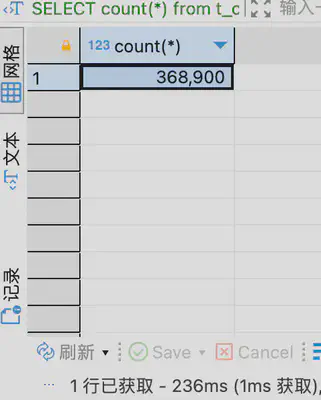
如果对字段tags_onehot_code建立btree索引,再执行如上语句,多次执行耗时均在160ms左右,不超过200ms
SELECT count(*) from t_combination_query_test tcqt WHERE tags_onehot_code like '__1__1_';
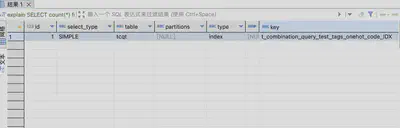
通过explain查看执行计划,可见此时执行该语句命中了btree索引,因此可以理解统计效率的提升,但是实际上效率从感官上提升不明显
explain SELECT count(*) from t_combination_query_test tcqt WHERE tags_onehot_code like '__1__1_';
返回满足条件的记录
需要注意的是,如果按如上的like查询条件是直接查询并返回结果集,查询过程是没有利用索引的,从结果导向可推测查询引擎在面对这种like模糊匹配 like '_1__1'必须进行全表扫描比对记录是否满足该模式。
-- 495ms
SELECT * from t_combination_query_test tcqt WHERE tags_onehot_code like '__1__1_';
当然,某些like模糊查询是有可能命中索引的(但是不保证),比如以下两种语句:
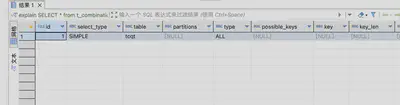
explain SELECT * from t_combination_query_test tcqt WHERE tags_onehot_code like '1__1___';
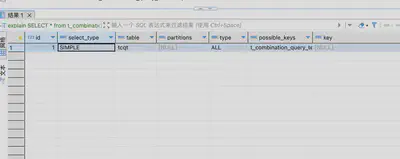
explain SELECT * from t_combination_query_test tcqt WHERE tags_onehot_code like '___1___';
通过explain查看执行计划,可以发现第一条语句的possible_keys不为空,而第二条语句的possible_keys为空,意味着前缀模糊匹配可能命中索引,这种可能性来自于b-tree索引的有序性。但是整体上来看,基于like模糊查询实现组合条件筛选难以利用索引(至少是难以利用主流索引b-tree、hash)。
思路2:将m个标签分成m个二元字段来存储,对m个字段建立联合索引
先来对数据表结构进行变更,通过位运算计算出每个字段的取值并更新表数据。
ALTER TABLE hero_test.t_combination_query_test ADD condition_1 TINYINT DEFAULT 0 NULL COMMENT '条件1';
ALTER TABLE hero_test.t_combination_query_test ADD condition_2 TINYINT DEFAULT 0 NULL;
ALTER TABLE hero_test.t_combination_query_test ADD condition_3 TINYINT DEFAULT 0 NULL;
ALTER TABLE hero_test.t_combination_query_test ADD condition_4 TINYINT DEFAULT 0 NULL;
ALTER TABLE hero_test.t_combination_query_test ADD condition_5 TINYINT DEFAULT 0 NULL;
ALTER TABLE hero_test.t_combination_query_test ADD condition_6 TINYINT DEFAULT 0 NULL;
ALTER TABLE hero_test.t_combination_query_test ADD condition_7 TINYINT DEFAULT 0 NULL;
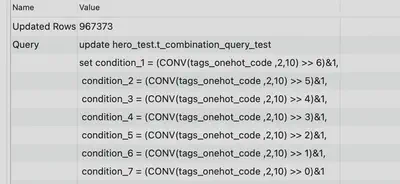
更新表数据:
update hero_test.t_combination_query_test
set condition_1 = (CONV(tags_onehot_code ,2,10) >> 6)&1,
condition_2 = (CONV(tags_onehot_code ,2,10) >> 5)&1,
condition_3 = (CONV(tags_onehot_code ,2,10) >> 4)&1,
condition_4 = (CONV(tags_onehot_code ,2,10) >> 3)&1,
condition_5 = (CONV(tags_onehot_code ,2,10) >> 2)&1,
condition_6 = (CONV(tags_onehot_code ,2,10) >> 1)&1,
condition_7 = (CONV(tags_onehot_code ,2,10) >> 0)&1;
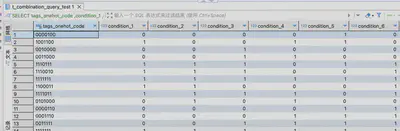
建好数据后,同样来尝试无索引版本和有索引版本的sql性能测试。
无索引版本
-- 1.4-1.760s
SELECT * from t_combination_query_test tcqt WHERE condition_3=1 and condition_6=1;
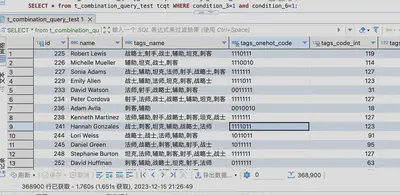
-- 900ms 276712行
SELECT * from t_combination_query_test tcqt WHERE condition_2=1 and condition_3=1 and condition_6=1;
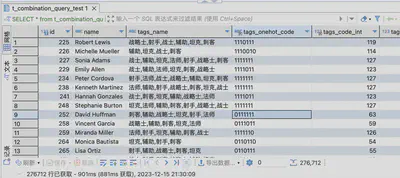
建立联合索引后查询
CREATE INDEX t_combination_query_test_condition_1_IDX USING HASH ON hero_test.t_combination_query_test (condition_1,condition_2,condition_3,condition_4,condition_5,condition_6,condition_7);
-- 726ms 368900
SELECT * from t_combination_query_test tcqt WHERE condition_3=1 and condition_6=1;
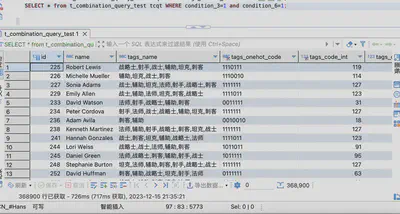
-- 800ms 276712
SELECT * from t_combination_query_test tcqt WHERE condition_2=1 and condition_3=1 and condition_6=1;
-- 147ms
SELECT count(*) from t_combination_query_test tcqt WHERE condition_3=1 and condition_6=1;
小结
上面的小测试,可以发现采用m个字段分别存储二元标签。联合索引加速的查询要比无索引的查询快几百毫秒,并且无论是否有索引,这种思路的查询耗时都比思路1的like查询耗时长。但是,对于统计数据量而言,思路2更快速。
思路3:使用onehot编码存储,但通过位运算进行筛选
MySQL中有一个CONV函数,可以对数值进行进制转换,对于以varchar类型存储的二进制数据,可以通过类似以下的语句转成数值型,并进行按位与运算实现组合条件筛选。
-- 18
SELECT CONV('1010010', 2,10) & CONV('0010010', 2,10);
-- 1
SELECT CONV('1010010', 2,10) & CONV('0010010', 2,10)=CONV('0010010', 2,10);
需要注意的是,直接对字符串型(文本类型)的“二进制”进行位运算得不到你想要的结果,按位操作需要针对整数或二进制数据。
-- 8474 wrong operation!
SELECT '1010010' & '0010010';
针对varchar类型的onehot编码作位运算
-- 1.300s 368900行
SELECT * from t_combination_query_test tcqt WHERE CONV(tags_onehot_code, 2,10) & CONV('0010010', 2,10) = CONV('0010010', 2,10);
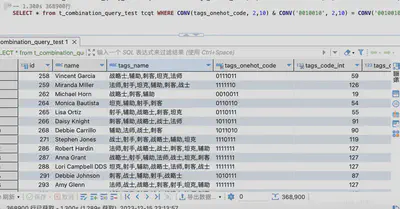
针对int类型的十进制编码作位运算
对整型数据作位运算,实际上是会直接在内存中对二进制数据作位运算/
-- 1.327s 368900行
SELECT * from t_combination_query_test tcqt WHERE CONV(tags_onehot_code, 2,10) & 18 = 18;
-- 784ms 368900行
SELECT * from t_combination_query_test tcqt WHERE tags_code_int & 18 = 18;
可见速度也较慢,不如like查询,究其原因,是因为这种位运算进行全表扫描,而like有可能走索引优化。
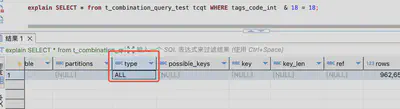
值得一提的是,如果是下面的语句,是可以走索引的。
-- 244ms
SELECT count(*) from t_combination_query_test tcqt WHERE tags_code_int & 18 = 18;
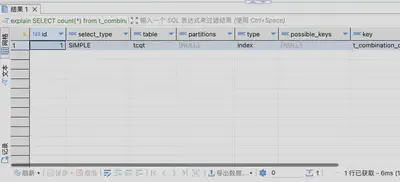
那么这里就有一个问题:为什么位运算select *不走索引,但select count(*)却能走索引?
思路4: 换一种角度思考组合的编码,并新建一个编码组合表
从前面的实验可以发现,能够利用索引的查询语句效率是会提高的(当然,这是一句废话),那么,如何能够让我们的多标签组合筛选能更充分地利用索引?我们发现前面的语句中位运算并没有利用b-tree索引加速查询,而是进行全表扫描
思路4考虑设计一种整型编码,能够表达出不同标签的组合,为整形编码加上索引,从而避免组合筛选时进行全表扫描。
参考Linux系统权限编码,对每类标签进行编码如下:
战士 1
坦克 2
辅助 4
法师 8
射手 16
刺客 32
战略士 64
我们认为每一种组合可以通过组合包含元素的编码之和进行表达,比如说:
| 示例组合 | 编码之和 | 分解 |
|---|---|---|
| 战士、坦克 | 3 | 1+2 |
| 坦克、辅助 | 6 | 2+4 |
| 坦克、刺客、战略士 | 98 | 2+32+64 |
你可能会提出一个问题,同一个数字能否同时表达多种类型组合?如果可以表达,那么上述做法似乎会存在歧义(类似哈希冲突),如果同一数字只能表达唯一确定的一种组合,那么上述做法就是合适的方向。
上面的问题转换成不太严谨的数学语言的话,相当于:从m个编码候选集(约束每个编码为2的幂指数,且对于一种组合而言其最多出现一次)中任选k个编码(命名为组合x),这k个编码之和是否可能与候选集中某j个编码(命名为组合y)之和相同?(其中组合x不等于组合y)。当然,你也可以思考,什么样的编码设计能够满足上述要求?但是,简单起见,先考虑前一个特例性问题。
简单论证一下“编码plus”的理论可行性
战士 1
坦克 2
辅助 4
法师 8
射手 16
刺客 32
战略士 64
观察一下,应该不难发现,$2^k$无法被拆分成$2^j+2^q+…+2^w$的形式,其中j、q、w、k均为整数且互不相等,k>j、k>q、k>w。因为$2^j+2^q+…+2^w$最大的情况下,也只能是$\sum_0^{k-1}2^i$,而这个最大的可能性也比$2^k$小(可以通过反证法或者数学归纳法来证明,此处不演示)。基于上述条件,可以推断对于任一编码组合A:{$2^i,2^j,…,2^k$},不存在另一个编码组合B(B!=A)满足A内元素之和等于B内元素之和,因为当我们考虑集合B中的最大元素x与集合A中的最大元素y,那么当x大于y的时候,显然B之和一定大于A之和;当x小于y的时候,显然B之和一定小于A之和;当x=y时,除非A、B剩下的元素均相等,否则A之和一定不等于B之和。
也就是说:对于上述的编码,任一种组合的元素之和与这个组合本身是一一对应关系!因此这种编码可行。
数据库实践
因此,我们只需要建立每一种类型标签“组合编码表”,每个“组合编码”唯一确定一个组合,通过对组合编码建立B-tree索引(之所以选择B-tree,是因为我们的查询会涉及到范围查询),理论上就可以快速检索满足不同组合条件的记录了。
让我们修改一下表结构,并新建一个组合编码字典表
ALTER TABLE hero_test.t_combination_query_test ADD combination_sum SMALLINT NULL COMMENT '编码组合之和';
CREATE TABLE hero_test.t_combincation_code (
id SMALLINT auto_increment NOT NULL COMMENT '组合ID',
combination_name varchar(100) NOT NULL COMMENT '组合标识',
code SMALLINT NULL COMMENT '组合编码',
CONSTRAINT t_combincation_code_PK PRIMARY KEY (id)
)
ENGINE=InnoDB
DEFAULT CHARSET=utf8mb4
COLLATE=utf8mb4_0900_ai_ci
COMMENT='组合编码字典表';
CREATE UNIQUE INDEX t_combincation_code_code_IDX USING BTREE ON hero_test.t_combincation_code (code);
插入数据

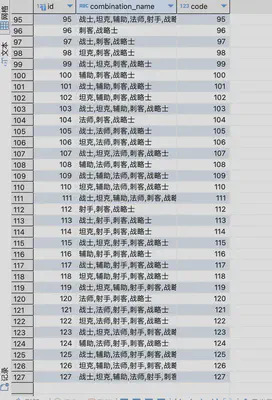
接下来,我们把每种组合条件转换成编码查询即可。
当然,细心如你,可能发现思路4在对标签编码存储的本质上与思路3是一样的,只是思路3从onehot编码的角度直接切入,思路4从类似linux权限的编码思路切入,并通过数学证明编码的稳定性,但是就标签编码方法上是殊途同归。但是思路4引入了一个组合编码表(这是之前的思路所没有的),接下来看这种改动是否能够加速查询。
统计查询
首先尝试select count(*)的查询,可以发现下面这种查询方式速度明显比之前的所有思路快。
-- 60ms-90ms
SELECT count(*) from t_combination_query_test tcqt where EXISTS (SELECT 1 from t_combincation_code tcc where tcc.code & 18=18 and tcqt.tags_code_int=tcc.code);
-- 50-60ms
SELECT count(*) from t_combination_query_test tcqt where EXISTS (SELECT 1 from t_combincation_code tcc where tcc.code & 50=50 and tcqt.tags_code_int=tcc.code);
-- 65-100ms
SELECT count(*) from t_combination_query_test tcqt where tags_code_int in (SELECT code from t_combincation_code tcc where code & 18=18);
-- 50-80ms
SELECT count(*) from t_combination_query_test tcqt where tags_code_int in (SELECT code from t_combincation_code tcc where code & 50=50);
通过查看执行计划可见每个步骤均利用了索引。

如果未对标签编码字段建索引,统计速度就会很慢, 对于测试数据集(百万量级)而言,统计速度相差十倍左右。
-- 758ms
SELECT count(*) from t_combination_query_test tcqt where combination_sum in (SELECT code from t_combincation_code tcc where code & 18=18);
-- 668ms
SELECT count(*) from t_combination_query_test tcqt where combination_sum in (SELECT code from t_combincation_code tcc where code & 50=50);

非统计查询,直接查询结果集
使用select where exist语法查询
-- 2.517s
SELECT * from t_combination_query_test tcqt where EXISTS (SELECT 1 from t_combincation_code tcc where tcc.code & 18=18 and tcqt.tags_code_int=tcc.code);
使用select in语法查询:
-- 4.41s
SELECT * from t_combination_query_test tcqt where tags_code_int in (SELECT code from t_combincation_code tcc where code & 18=18);
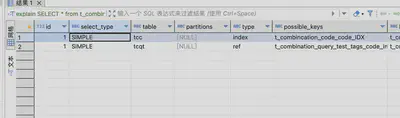
explain SELECT * from t_combination_query_test tcqt JOIN t_combincation_code tcc ON tcc.code=tcqt.tags_code_int where code & 18=18;
-- 2.72s
SELECT * from t_combination_query_test tcqt JOIN t_combincation_code tcc ON tcc.code=tcqt.tags_code_int where code & 18=18;
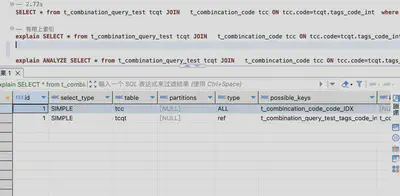
可见,引入组合编码表后的查询速度更慢。
拓展阅读
Linux文件权限
Linux系统对于权限的划分与组合是通过数值表示的,1代表可执行(x,execute)、2代表可写(w,write)、4代表可读(r,read),0表示没权限。我们把这些数字称为权限编码,不同权限对应的编码相加即可表示权限的组合,如6(6=2+4)表示可读可写,7(7=1+2+4)表示可读可写可执行。
位图索引
MySQL高阶调优
数据库性能测试工具
……